
【Copilot Studio】KPIの集計をLLMに任せず決定論的にやってみた:コードインタープリターとOffice Scriptの2アプローチ
はじめに
こんにちは、けーまです。
KPIレポートを作るとき、元データは月次で、レポートには四半期の合計・平均・前年比を載せたい、ということがよくあります。
このとき悩むのが「平均や前年比の計算をLLMに任せてよいか」です。
生成AIは文章の生成は得意ですが、数値の計算は桁を間違えたり対象を取り違えたりすることがあり、金額や比率の計算を任せるのは不安が残ります。
そこで本記事では、数値の集計を LLM にさせず、決定論的に行う2つのアプローチを取り上げ、2026年6月時点で実機検証しました。
エージェントの中で Python を実行するコードインタープリターと、Excel の Office Script(TypeScript)をフローから実行する方法です。どちらも、集計に使うコードを先に書いておいて固定する点は同じです。
収集したデータを正確に集計して資料化したい方の参考にしていただければと思います。
本記事は、Copilot Studio でエージェントを作るシリーズの第6回です。
シリーズ全体では「収集 → 集計 → グラフ → 示唆 → 資料化」を一気通貫で行うエージェントを目指しており、本記事はその「集計」を扱います。
対象読者:Copilot Studio で、数値の集計をLLMに任せず正確に行いたい方
シリーズ記事一覧
| 回 | テーマ | 記事 |
|---|---|---|
| 第1回 | 最初のエージェント | 初めてのエージェントを作ってみた |
| 第2回 | ナレッジ | ナレッジでファイルに基づく回答を試してみた |
| 第3回 | トピック・ツール・フロー | トピック・ツール・エージェントフローで「動き」を作り込む |
| 第4回 | テンプレート・自律トリガー・マルチエージェント | テンプレート・自律トリガー・マルチエージェントで構成を広げてみた |
| 第5回 | 収集(データの渡し方) | 集計用のKPIデータをエージェントに持たせる方法を比べてみた |
| 第6回 | 集計 | (本記事) |
前回(第5回)はKPIデータをエージェントに持たせる方法を比べました。今回はその次のステップとして、持たせたデータの「集計」を決定論的に行う方法に進みます。
1. 今回やること
集計(平均・前年比などの計算)をLLMにさせず、決定論的な手段で行います。
本記事では、それを2つのアプローチで試します。
- 月次の生データから、四半期の平均と前年比を集計する
- アプローチ1:コードインタープリター(Python)で集計する。プロンプトにPythonを埋め込んで計算を固定する
- アプローチ2:Office Script(TypeScript)で書いた処理を、Copilot Studio のエージェント フローから実行する
- 2つのアプローチの使い分けを整理する
検証には、これまでと同じ架空の SaaS 企業3社(CloudNova / StreamForge / Datapeak)の月次 KPI データ(架空)を使います。
2. なぜ集計をLLMにさせないのか
生成AIは、文章の生成は得意ですが、数値の計算は必ずしも正確ではありません。
平均や前年比を指示しても、桁を間違えたり、対象を取り違えたりすることがあります。
レポートの数値は正確であることが前提なので、計算は決定論的な手段に任せます。
LLMには「集計結果を踏まえた文章生成(示唆)」や「差し込み」だけを任せ、計算そのものは別の仕組みで行う、という分担にします。
3. 集計を固定する2つのアプローチ
集計をLLMにさせない方法を、本記事では2つのアプローチで試します。
どちらも、集計に使うコードをあらかじめ書いておいて固定する点は同じです。違いは「どこで計算が走るか」と「課金」です。
- アプローチ1:コードインタープリター(Python)。Copilot Studio がエージェントの中でPythonを実行して集計します。集計に使うPythonコードをプロンプトに埋め込んでおけば、その計算ロジックは(コードインタープリターが書き換えない限り)ほぼそのまま実行され、計算を固定できます。プレミアム機能です。
- アプローチ2:Office Script(TypeScript)。集計の処理を Excel の Office Script に書いておき、Copilot Studio のエージェント フローから実行します。事前に書いたコードがそのまま走るので、毎回まったく同じ結果になります。標準コネクタで動き、コードインタープリターのようなプレミアム課金(Copilot Credits)はかかりません。
「どこで計算が走るか」を図にすると、次のとおりです。
コードインタープリターは Copilot Studio の中で Python を、Office Script は Excel の中で TypeScript を実行し、どちらも集計結果をエージェントに返します。
| 観点 | コードインタープリター | Office Script |
|---|---|---|
| 計算する場所 | Copilot Studio が実行するPython | Excel が実行するOffice Script(TypeScript) |
| 計算ロジックの書き方 | プロンプトにPythonを埋め込む(ほぼそのまま実行される) | スクリプトに書く(毎回そのまま実行される) |
| 必要スキル | 自然言語+Python | TypeScript |
| ライセンス・課金 | プレミアム(Copilot Credits を消費) | 標準(プレミアム課金なし。本番フローはアクション分の容量を消費) |
| データの渡し方 | チャットに添付、またはナレッジ | OneDrive/SharePoint 上のファイルをフローで読む |
| 注意点 | 応答に分単位かかることがある | スクリプトを事前に書く必要がある |
Office Script の「追加コストなし」は、コードインタープリター(プレミアム=Copilot Credits を消費)との対比で、Copilot Credits が不要という意味です。ただし本番チャネルでエージェント フローを実行する場合は、標準コネクタでもエージェント フローのアクション分の Copilot Studio 容量を消費します(テスト実行は対象外)。
4. 検証に使うデータ
2つのアプローチを同じ土俵で比べるため、共通の検証データを先に用意します。
使うのは、これまでと同じ架空の SaaS 企業3社(CloudNova / StreamForge / Datapeak)の月次 KPI(架空)です。
前年比を出すために、前年同期のデータが要るので、3社×(2024年度 第3四半期・2025年度 第3四半期。いずれも10〜12月)の月次KPIを、1つの RawMonthly シートに持つExcelを用意します。
集計(平均・前年比)は各アプローチの決定論的な手段に任せるので、このファイルには集計用の数式やサマリーは入れず、生データだけを持たせます。
生データExcelの生成スクリプト(クリックすると展開します)
#!/usr/bin/env python3
"""前年比(YoY)集計の検証用Excelを生成する。
コードインタープリター(CI)に読ませる生データ。
3社×(2024年度 第3四半期・2025年度 第3四半期。いずれも10〜12月)の月次KPIを1つのRawMonthlyシートに持つ。
集計(合計・平均・前年比)はCIのPython(pandas)で決定論的に行う前提のため、
このファイルには集計用の数式やサマリーシートは入れない(生データだけを渡す)。
"""
from openpyxl import Workbook
from openpyxl.worksheet.table import Table, TableStyleInfo
OUT = "kpi-raw-data-yoy.xlsx"
# 生データ(架空)。2024年度 第3四半期は成長前の低めの値、2025年度 第3四半期は前年から伸びた値。
# (会社, 月, ARR(百万円), NRR(%), 営業利益率(%))
RAW = [
("CloudNova", "2024-10", 1600, 116, 11),
("CloudNova", "2024-11", 1625, 117, 11.5),
("CloudNova", "2024-12", 1650, 118, 12),
("StreamForge", "2024-10", 1160, 105, -1),
("StreamForge", "2024-11", 1180, 106, -0.5),
("StreamForge", "2024-12", 1200, 107, 0),
("Datapeak", "2024-10", 2450, 124, 16.5),
("Datapeak", "2024-11", 2500, 125, 17),
("Datapeak", "2024-12", 2550, 126, 17.5),
("CloudNova", "2025-10", 1900, 119, 13),
("CloudNova", "2025-11", 1950, 120, 13.5),
("CloudNova", "2025-12", 2000, 121, 14),
("StreamForge", "2025-10", 1280, 108, 0.5),
("StreamForge", "2025-11", 1300, 109, 1),
("StreamForge", "2025-12", 1320, 110, 1.5),
("Datapeak", "2025-10", 2750, 127, 18.5),
("Datapeak", "2025-11", 2800, 128, 19),
("Datapeak", "2025-12", 2880, 129, 19.5),
]
def main() -> None:
wb = Workbook()
ws = wb.active
ws.title = "RawMonthly"
ws.append(["Company", "Month", "ARR", "NRR", "OPM"])
for row in RAW:
ws.append(list(row))
table = Table(displayName="RawMonthly", ref=f"A1:E{len(RAW) + 1}")
table.tableStyleInfo = TableStyleInfo(
name="TableStyleMedium2", showRowStripes=True
)
ws.add_table(table)
wb.save(OUT)
print(f"saved {OUT}")
if __name__ == "__main__":
main()
上のスクリプトを make_excel_yoy.py として保存し、実行します。
pip install openpyxl
python make_excel_yoy.py
# 出力例
saved kpi-raw-data-yoy.xlsx
生成された kpi-raw-data-yoy.xlsx を Excel で開くと、3社×6か月(2024年・2025年の第3四半期)の月次 KPI が RawMonthly シートに並びます。
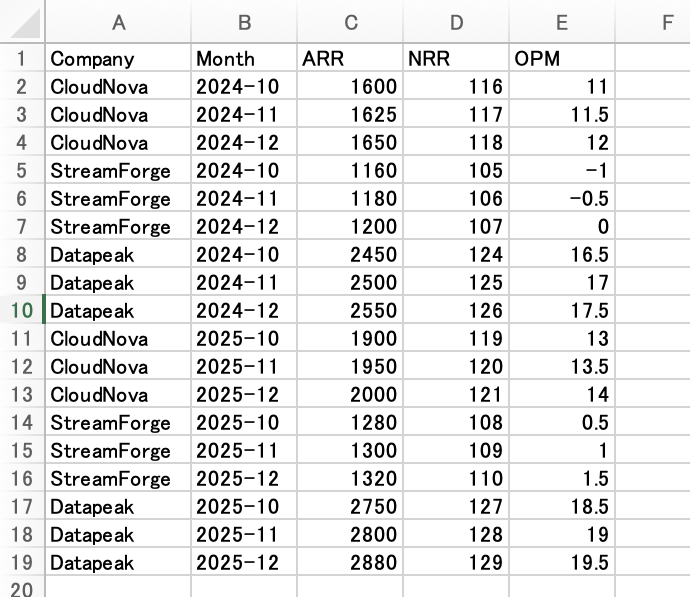
kpi-raw-data-yoy.xlsx の RawMonthly シート。CloudNova / StreamForge / Datapeak の3社について、2024年10〜12月と2025年10〜12月の月次 KPI(ARR・NRR・OPM)が並んでいる。集計用の数式やサマリーは入っておらず、生データだけを渡す
このファイルを各アプローチで集計させたとき、結果が次の値になれば「正しく集計できた」と判断します(合格基準)。
丸めは ARR・NRR が0桁、営業利益率(OPM)が1桁、前年比が1桁です。
| 会社 | 2024 ARR平均 | 2025 ARR平均 | ARR前年比 | 2025 NRR平均 | 2025 OPM平均 |
|---|---|---|---|---|---|
| CloudNova | 1625 | 1950 | +20.0% | 120 | 13.5 |
| StreamForge | 1180 | 1300 | +10.2% | 109 | 1.0 |
| Datapeak | 2500 | 2810 | +12.4% | 128 | 19.0 |
各値の計算方法は次のとおりです。
- ARR平均・NRR平均・OPM平均:その年の10〜12月の3か月を単純平均する(2024年・2025年とも同じ)。たとえば CloudNova の 2025年 NRR平均は (119 + 120 + 121) ÷ 3 = 120、2025年 OPM平均は (13 + 13.5 + 14) ÷ 3 = 13.5。2024年も同様に、NRR平均 (116 + 117 + 118) ÷ 3 = 117、OPM平均 (11 + 11.5 + 12) ÷ 3 = 11.5。
- ARR前年比(YoY):(2025年ARR平均 ÷ 2024年ARR平均 − 1) × 100。CloudNova なら 2025年ARR平均 (1900 + 1950 + 2000) ÷ 3 = 1950、2024年ARR平均 (1600 + 1625 + 1650) ÷ 3 = 1625 なので、(1950 ÷ 1625 − 1) × 100 = +20.0%。
アプローチ1(コードインタープリター)と アプローチ2(Office Script)は、どちらもこの kpi-raw-data-yoy.xlsx をそのまま使います。
それでは、まずアプローチ1(コードインタープリター)から見ていきます。
5. アプローチ1:コードインタープリターで集計する
5.1 コードインタープリターとは
コードインタープリターは、エージェントが必要に応じて Python を生成・実行し、CSV や Excel のような構造化ファイルを集計・分析できる機能です。
機能の詳細、課金(プレミアム機能で Copilot Credits を消費)、データの渡し方、有効化の手順は、第5回で扱いました。
詳しくは第5回「集計用のKPIデータをエージェントに持たせる方法を比べてみた」を参照してください。
本記事では、いちばん手軽な「チャットに添付」で集計させます。
5.2 プロンプトにPythonを埋め込んで計算を固定する
チャットにExcelを添付して「集計して」と頼むと、コードインタープリターがPythonを生成・実行して集計してくれます。
この基本的な使い方は第5回で扱ったので、本記事では一歩進めて、集計を決定論的に固定できるかに踏み込みます。
コードインタープリターは依頼のたびにPythonコードをAIが生成し直すため、「同じ集計を頼んでいるのに毎回コードが変わる」「本当に同じ計算をしているのか」という不安が残ります。
そこで、集計に使うPythonコードをプロンプトに丸ごと埋め込み、「生成し直さず、このコードのまま実行して」と指示して、計算を固定できるかを試しました。
テストチャットで、4章で用意した kpi-raw-data-yoy.xlsx を添付し、次のように依頼します。
次のPythonコードを、生成し直さず、このコードのまま code interpreter で実行してください。入力は添付したExcel(RawMonthlyシート)です。コード内の INPUT は添付ファイルのパスに置き換えてください。実行したコードと出力をそのまま見せてください。
import pandas as pd
df = pd.read_excel(INPUT, sheet_name="RawMonthly")
df["Year"] = df["Month"].astype(str).str[:4]
g = df.groupby(["Company","Year"], as_index=False).agg(ARR=("ARR","mean"), NRR=("NRR","mean"), OPM=("OPM","mean"))
order = ["CloudNova","StreamForge","Datapeak"]
rows = []
for c in order:
a24 = g[(g.Company==c)&(g.Year=="2024")].iloc[0]
a25 = g[(g.Company==c)&(g.Year=="2025")].iloc[0]
yoy = (a25.ARR / a24.ARR - 1) * 100
rows.append([c, round(a24.ARR), round(a25.ARR), f"{round(yoy,1):+}%", round(a25.NRR), round(a25.OPM, 1)])
result = pd.DataFrame(rows, columns=["会社","2024 ARR平均","2025 ARR平均","ARR前年比","2025 NRR平均","2025 OPM平均"])
print(result.to_string(index=False))
このプロンプトを、私の環境で合計6回実行しました。どれも同じプロンプト(同じ埋め込みPython)です。
結果はこうでした。出力値は6回とも同じ(4章の合格基準どおり)で、計算はぶれませんでした。
一方で、実際に実行されたコードは回によって違いました。違いが出たのは次の2か所です。
- ファイルを読み込む1行:埋め込んだ
pd.read_excel(INPUT, sheet_name="RawMonthly")のまま実行される回もあれば、Excelを一度CSVに変換してpd.read_csv(...)に書き換わる回もありました(プロンプトで「INPUTを添付ファイルのパスに置き換えて」と指示しているため、読み込み方はコードインタープリターに委ねられます)。 - クォート記法:6回のうち2回は、コード全体のダブルクォート
"..."がシングルクォート'...'に整形し直されていました。
逆に言うと、この2か所以外(groupby による平均・前年比・丸め・出力という集計ロジックそのもの)は、6回とも同じでした。6回の内訳は次のとおりです。
| 回 | 読み込み行 | クォート | 出力 |
|---|---|---|---|
| 1 | pd.read_csv('…RawMonthly.csv') |
ダブル | 合格基準 |
| 2 | pd.read_excel(INPUT, sheet_name=…) |
ダブル | 合格基準 |
| 3 | pd.read_csv(INPUT) |
シングル | 合格基準 |
| 4 | pd.read_csv(INPUT) |
シングル | 合格基準 |
| 5 | pd.read_excel(INPUT, sheet_name=…) |
ダブル | 合格基準 |
| 6 | pd.read_excel(INPUT, sheet_name=…) |
ダブル | 合格基準 |
1回目(左)と2回目(右)の実機画面でも、読み込み行が違うのに集計結果の表は一致しています。
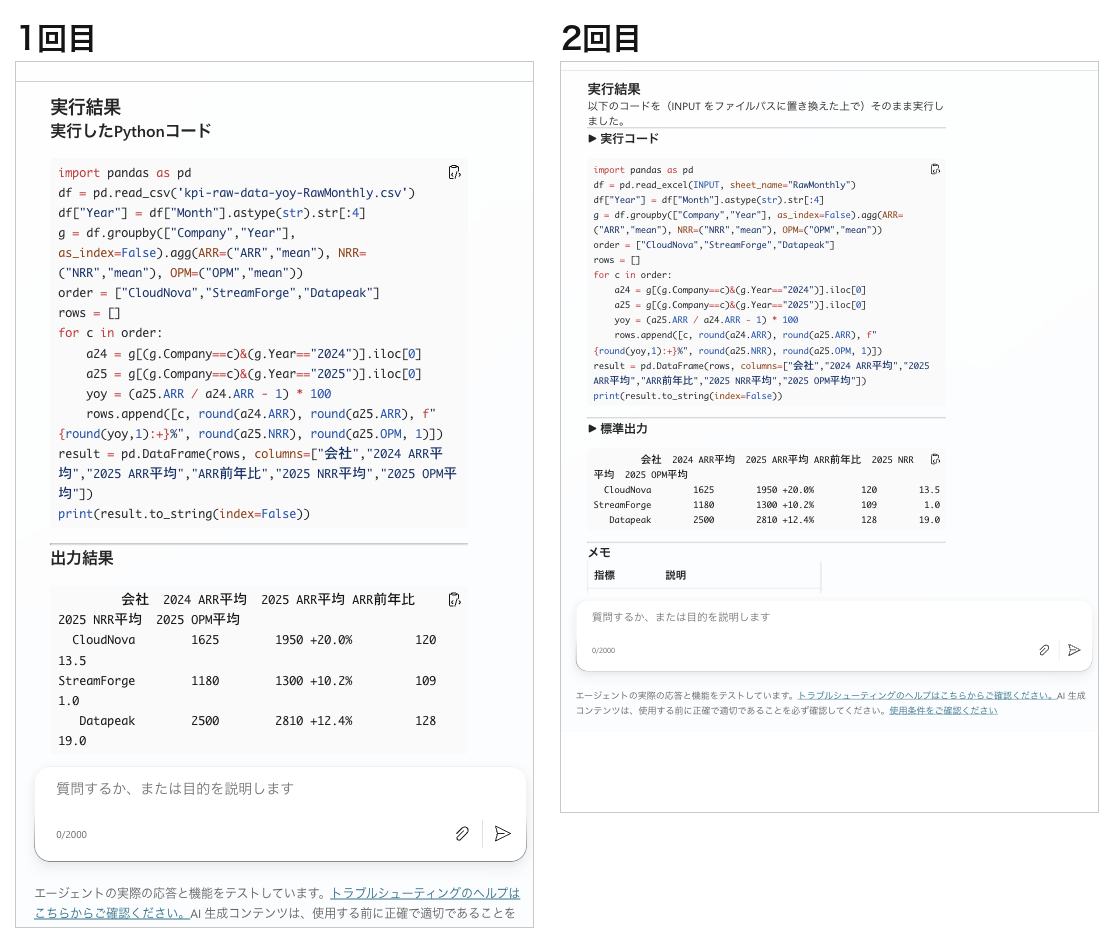
左が1回目、右が2回目(6回のうちの2回)。ファイルを読む1行が違う(1回目 pd.read_csv(...)/2回目 pd.read_excel(INPUT, ...))が、集計ロジックと出力(CloudNova +20.0%、StreamForge +10.2%、Datapeak +12.4%)は同じ
コードインタープリターのプロンプトでコードを一字一句固定するのは難しいです。プロンプトに入力した内容はLLMを介するので、変更されてしまう可能性があります。
実行コードまで1文字残らず毎回同じにしたいなら、次章の Office Script のように、あらかじめ書いたコードがそのまま走る手段が確実です。
5.3 コードインタープリターの注意点:応答に時間がかかる
コードインタープリターで集計するときに押さえておきたいのが、応答までの時間です。私の環境では、所要時間は1回目が約2.5分、2回目が約3分でした。それでも結果が返ったのは、時間制約のないテストチャットで直接実行したからです。
本番では、この集計を エージェント フロー(ツール)として呼び出すことになりますが、エージェント フローには「2分を超えると失敗」という時間制約があります。分単位かかりうるコードインタープリターは、この制約に当たりやすい点に注意が必要です。エージェント フローの応答時間の制約は Office Script とも共通なので、第7章にまとめました。
なお、本記事の検証自体は、いちばん手軽なテストチャットで行っています。
6. アプローチ2:Office Scriptで集計する
アプローチ2は、Excel の Office Script(TypeScript)で集計処理を書いておき、それを Copilot Studio の エージェント フローから実行する方法です。
5.2 のとおり、コードインタープリターは計算ロジックをプロンプトに埋め込めばほぼ固定できますが、ファイルの取り込み行までは一字一句固定されません。
「集計のコードを一度だけ書いて、毎回まったく同じに実行したい」なら、Office Script のように事前にコードを固定する方法が向きます。
Office Script は標準コネクタで動き、コードインタープリターのようなプレミアム課金(Copilot Credits)がかからず、AI が生成し直すこともありません。
Copilot Studio のツール追加画面でも、エージェント フローは「予測可能な自動化で、毎回同じ方法で実行される」と説明されており、コードインタープリターの「毎回生成」とは性質が異なります。
6.1 Office Script を書く
「Excelで処理を書く」というと VBA マクロを思い浮かべる方もいると思います。今回 VBA ではなく Office Script を使うのは、フロー(Copilot Studio のエージェント フロー)から呼び出せるのが Office Script だけだからです。主な違いは次のとおりです。
| 観点 | Office Script | VBA マクロ |
|---|---|---|
| 実行環境 | クラウド/クロスプラットフォーム(Excel for the web 中心。Windows/Mac デスクトップでも可) | デスクトップ専用(Windows/Mac) |
| 言語 | TypeScript(JavaScript) | VBA |
The fundamental difference is that VBA macros are developed for desktop solutions and Office Scripts are designed for secure, cross-platform, cloud-based solutions.
引用元: Differences between Office Scripts and VBA macros | Microsoft Learn
集計対象の kpi-raw-data-yoy.xlsx を Excel for the web で開き、「自動化」タブ → 「新しいスクリプト」 → 「コード エディターで作成」 から、次のスクリプトを保存します(ここでは名前を KPIQuarterAggYoY としました)。
RawMonthly シートを読み、会社×年でARR・NRR・OPMの平均を出し、ARRの前年比を計算して、CSV形式のテキストで返します。
Office Script(クリックすると展開します)
function main(workbook: ExcelScript.Workbook): string {
// RawMonthly(Company, Month, ARR, NRR, OPM)を会社×年で平均し、ARR前年比を決定論的に集計
const values = workbook.getWorksheet("RawMonthly").getUsedRange().getValues();
const map: { [k: string]: { arr: number[]; nrr: number[]; opm: number[] } } = {};
for (let i = 1; i < values.length; i++) {
const company = String(values[i][0]);
const year = String(values[i][1]).substring(0, 4);
const key = company + "|" + year;
if (!map[key]) map[key] = { arr: [], nrr: [], opm: [] };
map[key].arr.push(Number(values[i][2]));
map[key].nrr.push(Number(values[i][3]));
map[key].opm.push(Number(values[i][4]));
}
const mean = (xs: number[]) => xs.reduce((a, b) => a + b, 0) / xs.length;
let out = "会社,2024ARR平均,2025ARR平均,ARR前年比,2025NRR平均,2025OPM平均\n";
for (const c of ["CloudNova", "StreamForge", "Datapeak"]) {
const a24 = mean(map[c + "|2024"].arr);
const a25 = mean(map[c + "|2025"].arr);
const yoy = (a25 / a24 - 1) * 100;
out += `${c},${a24.toFixed(0)},${a25.toFixed(0)},${yoy >= 0 ? "+" : ""}${yoy.toFixed(1)}%,`
+ `${mean(map[c + "|2025"].nrr).toFixed(0)},${mean(map[c + "|2025"].opm).toFixed(1)}\n`;
}
return out;
}
上のコードがスクリプトの全文です。
Office Script には Python のような import 文はありません。main(workbook: ExcelScript.Workbook) が唯一の入口で、Excel を操作する ExcelScript API は最初から使えるため、追加の読み込みは不要です。
Each script must contain a
mainfunction with theExcelScript.Workbooktype as its first parameter. When the function runs, the Excel application invokes themainfunction by providing the workbook as its first parameter.
引用元: Fundamentals for Office Scripts in Excel | Microsoft Learn
スクリプトを保存して「実行」すると、私の環境では「スクリプトが正常に実行されました」と表示され、集計ロジックが動くことを確認できました。
6.2 エージェントフローでスクリプトを実行する
エージェントの 「ツールを追加する」→「エージェント フロー」 から、フローを新規作成します。
テンプレートにはトリガー 「エージェントがフローを呼び出したとき」 と 「Respond to the agent」 が用意されているので、その間に 「スクリプトの実行」(Excel Online (Business) コネクタ) を挟みます。
- スクリプトの実行:場所 = OneDrive for Business、ドキュメント ライブラリ = ドキュメント、ファイル =
/kpi-raw-data-yoy.xlsx、スクリプト =KPIQuarterAggYoY - Respond to the agent:テキスト出力
resultを1つ追加し、その値に「動的なコンテンツ」から「スクリプトの実行」の戻り値(result)を選ぶ(数式ではbody/result)
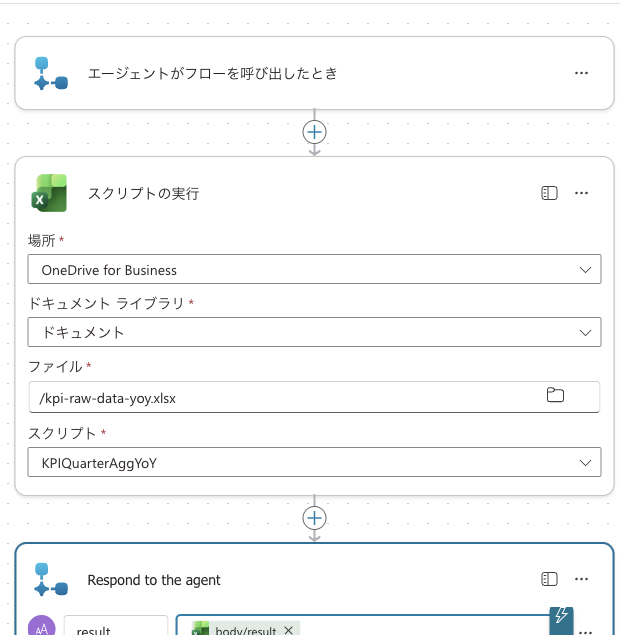
エージェントがフローを呼び出すトリガー(Skills)→「スクリプトの実行」(場所 = OneDrive for Business、ファイル = /kpi-raw-data-yoy.xlsx、スクリプト = KPIQuarterAggYoY)→「Respond to the agent」で出力 result にスクリプトの戻り値(result)を渡す
作成したフローは保存して公開します(エージェント本体の公開ではなく、フロー自体の公開です)。公開するとツールとしてエージェントに追加されます。
6.3 テストする
テストチャットから、このフローを実行するよう依頼します。
「KPIScriptAgg 四半期集計(Office Script・決定論)」ツールを実行して、返ってきた集計結果テキストをそのまま(加工せず)コードブロックで表示してください。
初回は Excel Online (Business) への接続を許可します(本人の資格情報での接続です)。
私の環境では、エージェントがフローを呼び出し、Office Scriptが返したCSVがそのまま返ってきました。値は4章の合格基準と一致しています。
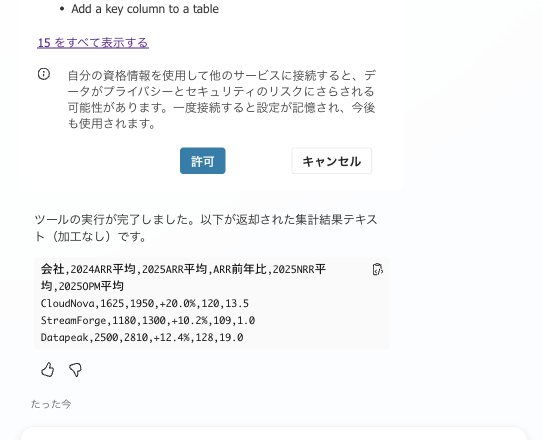
1回目。Excel Online への接続を許可後、フローが実行され、Office Scriptが返した集計CSV(CloudNova +20.0%、StreamForge +10.2%、Datapeak +12.4%)がそのまま返ってきた
新しい依頼でもう一度実行しても、まったく同じ値が返りました。事前に書いたスクリプトをそのまま実行するので、当然ですが結果は安定します。
2回目。同じツールを実行し、1回目と完全に同じCSVが返ってきた。コードインタープリターと違い、コードが生成し直されることはない
2回目は送信から十数秒で結果が返り、エージェント フローの応答時間の制約(同期応答は2分でタイムアウト・推奨100秒以内。詳細は次章)にも十分収まりました。
Office Script の強みは「時間制限がないこと」ではなく、固定したコードを毎回同じに実行できることです。今回の決定論的な集計はそもそも軽く、既定の同期応答(十数秒)で十分に収まりました。
7. エージェント フローの応答時間(共通の注意点)
コードインタープリターも Office Script も、本番ではエージェントが「エージェント フロー」をツールとして呼び出す形になります(本記事の検証はテストチャットで行いましたが、実運用はフロー経由です)。
このフローには、どちらのアプローチでも共通する「応答時間」の制約があるので、ここでまとめておきます。
7.1 既定は同期応答:2分でタイムアウト・100秒推奨
エージェント フローをツールとして呼ぶと、既定では同期応答になります。同期応答とは、エージェントがフローの応答をその場で待つ動きです。エージェントがいつまでも待つわけにはいかないので、2分を超えると失敗します。さらに Respond to the agent は100秒以内の応答が推奨されています。
By default, an agent or app initiates an agent flow that fails if it takes longer than two minutes to respond to the calling agent or app.
引用元: Speed up agent flow execution with express mode (preview) | Microsoft Learn
Respond to the agent within the 100 second action limit. Optimize the flow logic, queries, and the amount of data returned so that a typical run is below this 100 second limit.
引用元: Modify an existing flow to use with an agent | Microsoft Learn
つまり、コードインタープリター(私の環境で2.5〜3分かかった)のような重い処理を同期フローにそのまま載せると、2分制約でタイムアウトする恐れがあります。一方、今回の Office Script のような軽い集計は十数秒で収まり、問題ありません。「フローに載せれば時間制限がなくなる」わけではない点に注意してください。
7.2 重い後続処理は応答の後ろに回せる(最大30日)
応答そのものは2分以内(推奨100秒)に返す必要がありますが、時間のかかる処理を必ず2分に収めなければならないわけではありません。
Respond to the agent の後ろに置いた処理は、応答を返したあともバックグラウンドで最大30日まで続けられます。
ただし、その後続処理の結果は応答には含められません(応答はすでに返したあとだからです)。
Respond to the agent within the 100 second action limit. ... Actions in the flow that need to run longer can be placed after the Respond to the agent action to continue to run up to the flow run duration limit of 30 days.
引用元: Modify an existing flow to use with an agent | Microsoft Learn
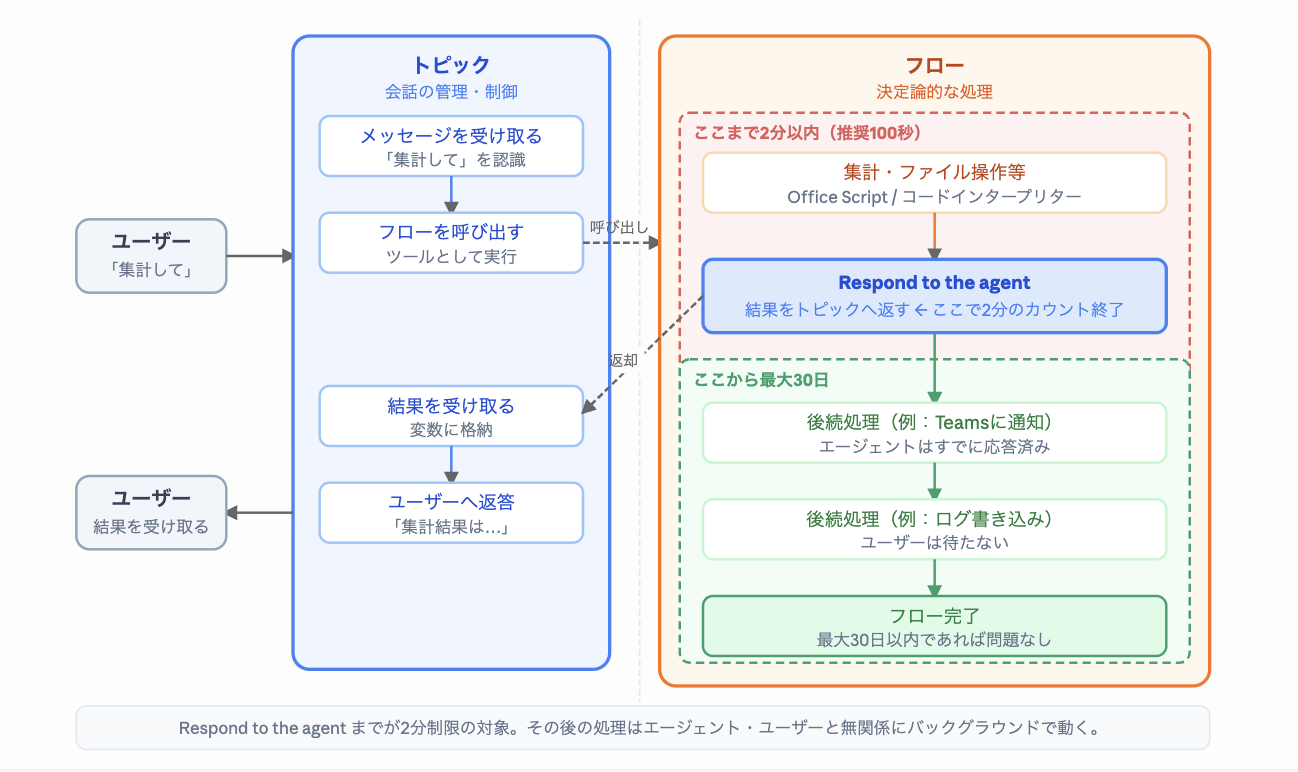
フローをツールとして呼び出し、「集計・ファイル操作(Office Script/コードインタープリター)→ Respond to the agent」までを2分以内(推奨100秒)に終えて結果を返す。Respond to the agent の後ろに置いた後続処理(例:Teams通知、ログ書き込み)は、ユーザーに応答したあとも最大30日までバックグラウンドで続く
8. 2つのアプローチの使い分け
実機で動かした結果、選び方は「毎回AIにコードを生成させてよいか」で整理できます。
- 前年比・予測・テーブル結合のように、集計を自然言語で柔軟に頼みたいなら、アプローチ1(コードインタープリター)。Pythonで計算でき、集計表やグラフ、Excelファイルも生成できる。ただしプレミアム課金で、応答に分単位かかることがある。プロンプトにコードを埋め込めば計算の中身(集計ロジック)と出力は固定できる(6回試して出力は全回一致)。ただしファイルの読み込み行やクォート記法など、実行コードの一字一句までは固定できない
- 集計ロジックを一度書いて、毎回まったく同じに実行したいなら、アプローチ2(Office Script)。TypeScript で書いた処理をフローから実行するので、プレミアム課金(Copilot Credits)がかからず、コードが生成し直されることもない
どちらも計算をLLMにさせない点は同じで、計算の中身は固定できます。
違いは、コードインタープリターは依頼ごとにAIがコードを組み立てるため、埋め込めば計算の中身と出力は固定できるものの読み込み行やクォート記法などは回ごとに変わりうるのに対し、Office Script は事前に書いたコードが1文字も変わらずそのまま走る点です。
最終ゴールの一気通貫エージェントでは、軽い固定集計はOffice Script、柔軟な分析はコードインタープリター、と役割を分けて持たせる形が現実的です。
9. まとめ
集計をLLMに任せず決定論的な手段で行えば、レポートの数値の正確さを保てます。
本記事では2つのアプローチを試しました。
Office Script は、事前に書いた TypeScript がそのまま走るので、同じ入力に常に同じ結果を返します。
コードインタープリターは、集計に使うPythonコードをプロンプトに埋め込めば、計算の中身(集計ロジック)と出力を固定でき、6回試して毎回同じ値が返ることを確認しました。ただしファイルの読み込み行やクォート記法など、実行コードの一字一句までは固定できません。
使い分けの軸はシンプルで、集計内容が決まっていて確実に同じ処理で実行したいならプレミアム課金のかからない Office Script、前年比や予測のように柔軟な分析が要るならコードインタープリター(プレミアム)を選びます。
なお、同期応答の時間制約(2分でタイムアウト・推奨は100秒以内)はコードインタープリターにもエージェント フローにも共通で、「フローなら制限がない」わけではない点には注意が必要です。
今回の検証では、2つのアプローチが同じ値を返しました。
ただし、これは両方を同じ集計ロジック・同じ丸めで書いたから一致しただけで、別々の実装(Python と Office Script)である以上、書き方がずれれば結果は食い違いえます。
「2つの手段だから必ず同じ値になる」とは限らないので、両方を併用するなら、結果を突き合わせて一致を確かめるのが安全です。
いずれにせよ、計算そのものは決定論的な手段に任せ、LLMには差し込みと示唆の文章生成だけを任せればよい、という分担を確認できました。
次回は、この集計値をグラフにします。








