
Google Chat Bot の回答をリッチテキスト化したら、Cards V2 の HTML 制約と向き合うことになった話
はじめに
第1回で Google Chat Bot を Cloud Functions + Python + uv で構築し、第2回で cardsV2 のプログレッシブ更新 UX を実装し、第3回で Vertex AI RAG Engine によるナレッジベース検索を組み込みました。
RAG パイプラインが動くようになり、ボットはユーザーの質問にそれなりに的確な回答を返せるようになりました。しかし、ひとつ気になることが。
回答がすべてプレーンテキストで、読みにくい。
Gemini が生成した回答には箇条書きや太字が含まれているのに、Cards V2 の textParagraph ウィジェットにそのまま渡すと、Markdown の記号がそのまま表示されてしまいます。**太字** は太字にならず、- リスト項目 はただのハイフン付きテキストになる。
「Cards V2 ってスタイリング対応してないのかな…」と思って調べ始めたのが、今回の話のきっかけです。
Cards V2 の textParagraph が対応する HTML タグ
調べてみると、Google Chat の textParagraph ウィジェットは Markdown ではなく、制限された HTML サブセット に対応していました。
対応タグ一覧
| タグ | 用途 |
|---|---|
<b> |
太字 |
<i> |
斜体 |
<u> |
下線 |
<s> |
取り消し線 |
<font color="..."> |
テキスト色 |
<a href="..."> |
リンク |
<br> |
改行 |
<code> |
インラインコード |
<pre> |
コードブロック |
<ul>, <ol>, <li> |
リスト |
<time> |
時刻表示 |
非対応タグ(使うとそのまま文字列として表示される)
<h1>〜<h6>— 見出しなし<strong>,<em>—<b>,<i>を使う必要がある<img>— 画像埋め込み不可<table>— テーブル不可<blockquote>— 引用ブロック不可<div>,<span>— 汎用コンテナ不可- CSS — 一切使えない
つまり、HTML は使えるが、使えるタグがかなり限られている。見出しもテーブルも使えない。<strong> すら使えず <b> でないとダメ。なかなかクセの強い制約です。
変換戦略: LLM → Markdown → 制限 HTML
ここで設計上の判断が必要になりました。
選択肢 A: LLM に直接制限 HTML を出力させる
選択肢 B: LLM には Markdown を出力させ、変換エンジンで制限 HTML に変換する
選択肢 A は一見シンプルですが、問題があります。LLM に <b> や <font color> を直接生成させると、トークン効率が悪い上に、対応タグの一覧をシステムプロンプトに入れる必要があり、本来の回答品質に使うべきコンテキストを圧迫します。
選択肢 B を採用しました。理由:
- Markdown はトークン効率がよい —
**太字**は<b>太字</b>より短い - LLM は Markdown が得意 — 事前学習で大量の Markdown を学習済み
- 変換ロジックを分離できる — LLM のプロンプトは「何を答えるか」に集中させ、「どう表示するか」は変換レイヤーで吸収する
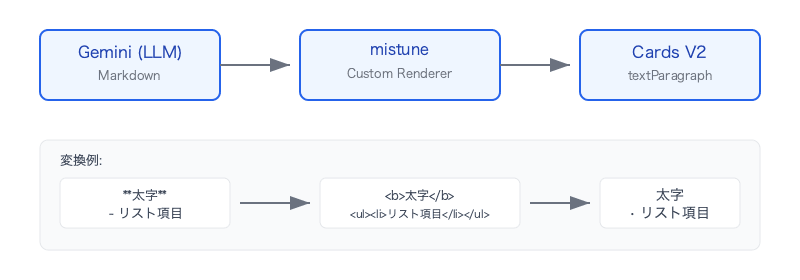
変換エンジンの実装: mistune カスタムレンダラー
変換エンジンには mistune 3.x を採用しました。mistune は HTMLRenderer をサブクラス化するだけでレンダリングを完全にカスタマイズでき、今回の「標準 HTML ではなく制限 HTML サブセットに変換する」という要件にぴったりでした。
タグマッピング
まず、Markdown の各要素を Cards V2 対応タグにマッピングします。
class _ChatHTMLRenderer(mistune.HTMLRenderer):
# 見出し → <b>(<h1>〜<h6> は非対応のため)
def heading(self, text, level, **attrs):
return f"{_BLOCK_SEP}<b>{text}</b>\n"
# 強調 → <i>(<em> は非対応)
def emphasis(self, text):
return f"<i>{text}</i>"
# 太字 → <b>(<strong> は非対応)
def strong(self, text):
return f"<b>{text}</b>"
# 画像 → <a>リンク(<img> は非対応)
def image(self, text, url, title=None):
label = text or "image"
return f'<a href="{url}">{label}</a>'
# 引用 → <i>(<blockquote> は非対応)
def block_quote(self, text):
inner = text.replace(_BLOCK_SEP, "").strip()
return f"{_BLOCK_SEP}<i>▎ {inner}</i>\n"
ポイントは、Cards V2 が対応していないタグを対応タグで代替するところです。<h1> の代わりに <b>、<blockquote> の代わりに <i> + 視覚的なインジケータ ▎。完璧ではありませんが、プレーンテキストよりはるかに読みやすい。
ブロック分割: \x00 センチネルパターン
変換エンジンの設計で一番考えたのがブロック分割です。
Cards V2 では、回答テキストを複数の textParagraph ウィジェットに分割して配置します。以前は answer.split("\n\n") で分割していましたが、これだとリストやコードブロックの途中で分断されてしまう問題がありました。

解決策として、レンダラーの各ブロックレベル要素の出力に \x00(NULL文字)センチネル を挿入し、最終的にこのセンチネルで分割するパターンを採用しました。
_BLOCK_SEP = "\x00" # 実コンテンツには出現しない
class _ChatHTMLRenderer(mistune.HTMLRenderer):
def paragraph(self, text):
return f"{_BLOCK_SEP}{text}\n" # 段落の先頭にセンチネル
def list(self, text, ordered, **attrs):
tag = "ol" if ordered else "ul"
inner = text.replace(_BLOCK_SEP, "") # ネストされたリストのセンチネルを除去
return f"{_BLOCK_SEP}<{tag}>\n{inner}</{tag}>\n" # リスト全体で1つのセンチネル
def block_code(self, code, info=None):
escaped = mistune.escape(code)
return f"{_BLOCK_SEP}<pre><code>{escaped}</code></pre>\n" # コードブロック全体で1つ
def markdown_to_chat_html(text: str) -> list[str]:
raw: str = _markdown(text)
return [s.strip() for s in raw.split(_BLOCK_SEP) if s.strip()]
こうすることで、リストは <ul> 全体が1つのウィジェットに収まり、コードブロックも分断されません。段落は自然に分割されます。
セキュリティ: 生 HTML のエスケープ
mistune のデフォルトレンダラーは block_html と inline_html で生 HTML をそのまま出力します。LLM の出力にユーザー入力がそのまま含まれる可能性があるため、これらをエスケープする処理を追加しました。
def block_html(self, html):
return f"{_BLOCK_SEP}{mistune.escape(html)}\n"
def inline_html(self, html):
return mistune.escape(html)
コードブロック内のHTMLも同様にエスケープしています。<script>alert('xss')</script> のような入力が <script> に変換され、安全に表示されます。
システムプロンプトによる LLM 出力制御
変換エンジンだけでは不十分です。LLM が Cards V2 非対応の Markdown 記法を使ってしまうと、変換後の見栄えが悪くなります。
例えば、LLM が ## 見出し を使うと、変換後は <b>見出し</b> になります。これ自体は動きますが、見出しの後に改行が入らないなど、レイアウトが崩れることがあります。テーブル記法 | A | B | は変換エンジンが対応していないため、そのままパイプ文字が表示されてしまいます。
そこで、システムプロンプトに ## 回答のフォーマット セクションを追加し、LLM の出力を制御しました。
## 回答のフォーマット
- Markdownで回答してください
- 手順を説明する場合は番号付きリスト(1. 2. 3.)を使う
- 複数の項目を並列で列挙する場合は箇条書き(- )を使う
- 重要なキーワードやボタン名・メニュー名は **太字** にする
- コマンドやパス名は `インラインコード` で囲む(ただしURLは除く)
- URLは `インラインコード` ではなくMarkdownリンク `[表示テキスト](URL)` で記載する
- 見出し(##)は使わず、太字(**見出し**)で代用する
- テーブル記法は使わない(箇条書きで代用する)
- 回答は短い導入文 → 本体(リスト/手順) → 補足の順で構成する
重要なのは禁止ルールです。見出しとテーブルを禁止し、代替手段を明示しています。LLM に「使うな」とだけ言うと別の問題が起きるため、「代わりにこれを使え」まで指示するのがコツです。
ステータス UI の色分け: <font color> の活用
変換エンジンを実装していて気づいたのが、<font color> タグが使えることです。これを活かして、プログレッシブカードのステータス行を色分け表示にしました。
status_label = state.current_step_description
if state.status == PipelineStatus.COMPLETED:
status_text = f'<font color="#188038"><b>✅ {status_label}</b></font>'
elif state.status == PipelineStatus.FAILED:
status_text = f'<font color="#d93025"><b>❌ {status_label}</b></font>'
else:
status_text = f'<font color="#1a73e8"><b>⏳ {status_label}</b></font>'
| ステータス | 色 | 表示 |
|---|---|---|
| 処理中 | 青 #1a73e8 |
⏳ 回答を生成中 |
| 完了 | 緑 #188038 |
✅ 4 ステップ完了 |
| 失敗 | 赤 #d93025 |
❌ エラーが発生しました |
色はGoogle のマテリアルデザインパレットから選んでいます。<font color> + <b> + 絵文字の組み合わせで、プレーンテキストのステータス行とは一目で区別がつくようになりました。
テスト: 非対応タグの漏れ検出
変換エンジンのテストでは、個別の変換テストに加えて、非対応タグが出力に漏れていないことを検証するテストを書きました。
class TestNoUnsupportedTags:
def test_full_document(self):
md = """# Title
Some **bold** and *italic* text.
## Section
1. First step
2. Second step
- Bullet one
- Bullet two
> A quote
¥`¥`¥`python
print("hello")
¥`¥`¥`

---
End.
"""
result = markdown_to_chat_html(md)
full = " ".join(result)
for tag in [
"<h1", "<h2", "<h3", "<h4", "<h5", "<h6",
"<p>", "<p ", "<strong>", "<em>", "<del>",
"<blockquote>", "<img", "<hr", "<table",
"<div", "<span",
]:
assert tag not in full, f"Unsupported tag {tag} found in output"
Markdown のあらゆる要素を含む文書を変換し、Cards V2 非対応のタグが1つも出力されていないことを確認しています。新しい Markdown 記法への対応を追加したときにも、このテストが安全網になります。
運用で発覚した落とし穴
本番運用を開始してから、テスト時には気づかなかった2つの問題が見つかりました。どちらもエラーにはならず、表示が崩れるだけなので発見が遅れました。
落とし穴 1: ネストされたリストがウィジェットを分断する
ユーザーの質問に対して、ボットがこんな番号付きリスト(一部にサブリスト付き)を返す場面がありました。
1. **Googleドライブのアイコン** をクリックします。
- アイコンが見当たらない場合は「∧」マークをクリック
2. **歯車のアイコン**(設定)をクリックします。
3. **終了** をクリックして、アプリを閉じます。
期待する表示は番号付きリストが1つのブロックとしてレンダリングされることですが、実際には 項目2と3がリストから飛び出して、番号なしのプレーンテキストとして表示 されていました。
原因は、センチネルパターンの _BLOCK_SEP がネストされたリストの内部にも挿入されていたことです。mistune のレンダリングフローを追うと:
- 項目1のサブリスト
- アイコンが〜に対して、内側のlist()が呼ばれる - 内側の
list()も_BLOCK_SEPを先頭に挿入する - 外側の
list()がすべてのlist_itemを結合して<ol>で囲む - 最終的に
split(_BLOCK_SEP)すると、外側リストの途中で分断される
セグメント0: <ol><li>項目1のテキスト... ← <ol>が閉じられていない
セグメント1: <ul><li>サブ項目</li></ul></li><li>項目2</li><li>項目3</li></ol>
↑ <ol>の外に出てしまう
各セグメントは別々の textParagraph ウィジェットになるため、セグメント1は <ol> のコンテキストを失い、項目2と3が番号なしで表示されます。
修正は block_quote と同じパターンで、list() 内でネストされたセンチネルを除去するだけです。
def list(self, text, ordered, **attrs):
tag = "ol" if ordered else "ul"
inner = text.replace(_BLOCK_SEP, "") # ネストされたリストのセンチネルを除去
return f"{_BLOCK_SEP}<{tag}>\n{inner}</{tag}>\n"
block_quote() では最初からこの処理を入れていたのに、list() では見落としていました。ブロックレベル要素がネストされうるメソッドでは、内側の _BLOCK_SEP を必ず除去する というルールを徹底すべきでした。
落とし穴 2: URL がリンクではなくコードブロックとして表示される
ナレッジベースの記事に URL が含まれている場合、ボットの回答に URL が含まれることがあります。ところが、表示された URL が クリックできないコードブロック になっていました。
原因は2つありました。
原因 A: システムプロンプトの指示が曖昧だった
- コマンドやパス名は `インラインコード` で囲む
この指示を受けた LLM は、URL を「パス名」と解釈して `https://example.com/...` のようにバッククォートで囲んでしまいます。変換エンジンはこれを忠実に <code>https://example.com/...</code> に変換するため、クリックできないコードブロックとして表示されます。
修正として、URL を明示的に除外し、Markdown リンク記法を使うよう指示を追加しました。
- コマンドやパス名は `インラインコード` で囲む(ただしURLは除く)
- URLは `インラインコード` ではなくMarkdownリンク `[表示テキスト](URL)` で記載する
原因 B: 裸の URL が自動リンクされなかった
プロンプトを修正しても、LLM が Markdown リンク記法を使わずに裸の URL をそのまま出力するケースがあります。mistune のデフォルトでは裸の URL はプレーンテキストのまま出力されるため、クリックできません。
mistune の url プラグインを有効にすることで、裸の URL を自動的に <a> タグでラップするようにしました。
_markdown = mistune.create_markdown(
renderer=_ChatHTMLRenderer(),
plugins=["strikethrough", "url"], # url プラグインを追加
)
プロンプト修正(LLM の出力を正す)と自動リンク(変換エンジンのフォールバック)の二重対策により、URL が確実にクリック可能なリンクとして表示されるようになりました。
まとめ
Google Chat Cards V2 の textParagraph は、使えるHTMLタグが限られているという制約がありますが、工夫次第でかなりリッチな表示が実現できます。
今回学んだことを整理すると:
- Cards V2 は Markdown ではなく制限 HTML — 対応タグを把握した上で、変換レイヤーを挟むのが現実的
- LLM → Markdown → 制限 HTML のパイプライン — LLM にはトークン効率の良い Markdown を出力させ、表示の責務は変換エンジンに分離する
- ブロック分割にはセンチネルパターン —
split("\n\n")ではリスト/コードブロックが分断される。レンダラー内でブロック境界を明示するのが確実 - ネスト可能なブロック要素は内側のセンチネルを除去する —
list()やblock_quote()など、ブロック要素を内包できるメソッドでは_BLOCK_SEPの除去が必須。これを忘れるとウィジェットが分断される - システムプロンプトで非対応記法を禁止 — 「使うな」だけでなく「代わりにこれを使え」まで指示する。URL のように「パス名に似ているが別物」なケースは明示的に除外する
<font color>は意外と便利 — ステータス表示の視認性が大幅に向上する- 表示崩れはエラーにならない — ログにはエラーが出ず、実際の画面を見ないと気づけない。本番で定期的に回答の表示を目視確認する運用が重要
Cards V2 の HTML 制約は一見厳しいですが、逆に言えば対応タグが少ない分、変換エンジンのロジックはシンプルに保てます。mistune のカスタムレンダラーで約 80 行、テスト込みでも 200 行以下。投資対効果は高いと思います。










