
httplib2 のスレッドセーフティ問題を修正した話 — google-api-python-client の罠
はじめに
Google Chat Bot のシリーズ記事です。第1回で Cloud Functions + Python + uv の最小構成、第2回で cardsV2 プログレッシブ UX、第3回でリッチテキスト対応、第4回で Vertex AI RAG Engine によるナレッジベース検索を実装しました。
今回の話は「バグ修正」です。OOM エラーを直した直後に表面化した、もう一つの厄介な問題 — httplib2 の共有 TCP/SSL 接続がマルチスレッドで壊れる — を調査・修正した過程を共有します。
症状: 連投するとランダムにエラーが出る
ボットのメモリを 1Gi → 2Gi に増やして OOM を解消した直後、新たな問題が発覚しました。ユーザーが短時間に複数のメッセージを送ると、一部のメッセージが「エラーが発生しました」カードで返ってくるのです。
Cloud Logging を確認すると、以下のエラーが散発的に記録されていました:
05:11:31 ERROR Failed to create initial card (SSLError)
05:12:21 ERROR Failed during pipeline execution (SSLError)
05:13:21 ERROR Failed during pipeline execution (SSLError)
05:15:01 ERROR Failed during pipeline execution (SSLError)
05:16:01 ERROR Failed to send error card (TimeoutError)
具体的なエラーは3種類:
| エラー | 内容 |
|---|---|
ssl.SSLError: [SSL: WRONG_VERSION_NUMBER] |
TLS ハンドシェイク状態が壊れている |
TimeoutError: The read operation timed out |
別スレッドのレスポンスを待ってしまう |
http.client.IncompleteRead |
レスポンスが途中で切れる |
ポイント: OOM ではない。メモリは十分にある。エラーはすべて HTTP 通信層で起きている。
根本原因: httplib2.Http はスレッドセーフではない
アーキテクチャの確認
まず、このボットのリクエスト処理の流れを整理します:
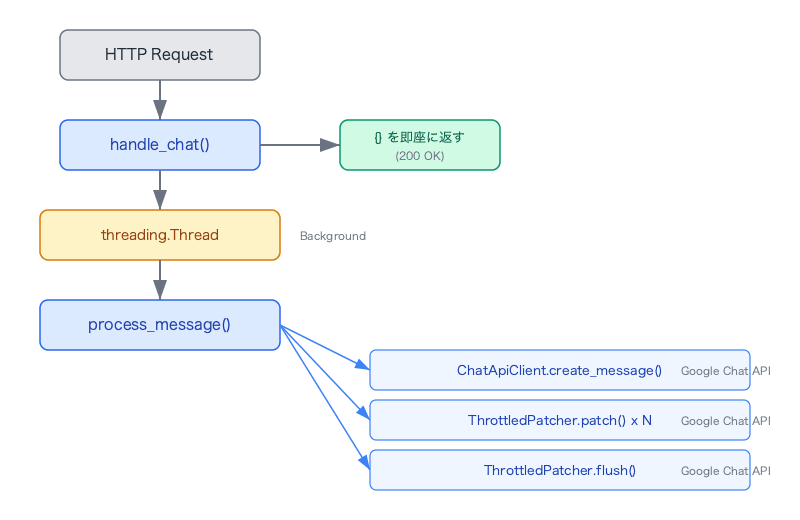
main.py でリクエストを受け取った瞬間に {} を返し、実際の処理はバックグラウンドスレッドで実行します(Cloud Functions gen2 は --no-cpu-throttling で HTTP レスポンス後も CPU が使える)。
問題の箇所
ChatApiClient は Google Chat API との通信を担うクラスで、内部で googleapiclient の service オブジェクトを使います。この service オブジェクトはディスカバリドキュメントのパースが重いため、シングルトンパターンで一度だけ生成していました:
# bot/chat_api.py(修正前)
_default_service = None
_lock = threading.Lock()
def _get_default_service():
global _default_service
if _default_service is None:
with _lock:
if _default_service is None:
credentials, _ = google.auth.default(scopes=SCOPES)
doc = json.loads(_DISCOVERY_DOC_PATH.read_text())
_default_service = build_from_document(doc, credentials=credentials)
return _default_service
ダブルチェックロッキングで初期化自体はスレッドセーフです。問題はその先 — build_from_document() が内部で生成する httplib2.Http インスタンスを、全スレッドが共有してしまうことです。
「スレッドセーフ」とは、複数のスレッドが同時にアクセスしても正しく動作することを意味します。
プログラムが複数の処理を並行して実行する場合、それぞれの処理は「スレッド」という単位で動きます。問題は、複数のスレッドが同じデータ(変数、接続、ファイルなど)を同時に読み書きするときに起きます。
身近な例で説明すると、1つのノートを2人が同時に書き込むようなものです:
- Aさんが「今日の天気は」と書く
- Bさんが同時に同じ行に「会議の議題は」と書く
- 結果: 「今日会議天の気議は題は」— 意味不明な文字列になる
これと同じことが、プログラムの中でも起きます。スレッドセーフなコードでは、「1人が書いている間は他の人は待つ」(ロック)や「そもそも別々のノートを使う」(インスタンス分離)といった仕組みで、この問題を防ぎます。
今回のケースでは、httplib2.Http が保持する TCP/SSL 接続(=ノート)を複数のスレッド(=人)が同時に使ってしまい、通信データが壊れていました。
httplib2 は Python の HTTP クライアントライブラリで、requests や httpx と同じ領域のツールです。2006年に登場し、当時は標準ライブラリの urllib にはなかったキャッシュ制御や認証の自動処理など先進的な機能を持っていました。google-api-python-client は初期からこのライブラリに依存しており、現在もデフォルトの HTTP トランスポートとして使われています。
現代の Python 開発で HTTP クライアントといえば requests や httpx が主流ですが、これらとの大きな違いはスレッドセーフティです:
| ライブラリ | スレッドセーフ | 接続管理 |
|---|---|---|
httplib2.Http |
No | 1インスタンスが内部に接続キャッシュ(dict)を保持。ロックなし |
requests.Session |
No | 同様にスレッドセーフではないが、公式ドキュメントに明記されている |
httpx.Client |
Yes | 内部でコネクションプールを管理し、スレッドセーフに設計 |
requests.Session もスレッドセーフではありませんが、requests は通常 requests.get() のようなモジュールレベル関数で使うため問題になりにくいです。一方 httplib2 は Http() インスタンスを明示的に作って使う設計であり、かつ google-api-python-client がそのインスタンスを service 内部に隠蔽してしまうため、共有していることに気づきにくいのです。
なぜ壊れるのか
httplib2.Http は内部に TCP/SSL 接続を保持しますが、それらをスレッド間で安全に共有する仕組みがありません。2つのスレッドが同時に .execute() を呼ぶと:
- スレッド A が TLS ハンドシェイクを開始
- スレッド B が同じソケットに別のリクエストを流す
- TLS の状態マシンが矛盾 →
WRONG_VERSION_NUMBER
あるいは:
- スレッド A がリクエストを送信し、レスポンスを待つ
- スレッド B が同じソケットでリクエストを送信
- スレッド A がスレッド B のレスポンスを読んでしまう →
IncompleteRead
1〜2リクエスト/秒なら偶然動くこともありますが、10件同時に送ると高確率で壊れます。
Google の公式ドキュメントを調べてみた
google-api-python-client の公式スレッドセーフティドキュメントには、はっきりと書いてあります:
The httplib2.Http() objects are not thread-safe. If you are running as a multi-threaded application, each thread that you are making requests from must have its own instance of httplib2.Http().
公式が推奨する解決方法は2つ:
Approach 1: requestBuilder をオーバーライド
def build_request(http, *args, **kwargs):
new_http = google_auth_httplib2.AuthorizedHttp(credentials, http=httplib2.Http())
return googleapiclient.http.HttpRequest(new_http, *args, **kwargs)
service = discovery.build('api_name', 'api_version',
requestBuilder=build_request, http=authorized_http)
service 自体に「API コールごとに新しい Http を作る」振る舞いを組み込む方法です。
Approach 2: execute() に http を渡す
http = google_auth_httplib2.AuthorizedHttp(credentials, http=httplib2.Http())
service.spaces().messages().create(...).execute(http=http)
.execute() 呼び出し時に明示的に Http インスタンスを渡す方法です。
5つのアプローチを比較した
公式ドキュメント以外に、DoIt の本番運用記事や GitHub Issues も調査し、5つのアプローチを比較しました。
| # | アプローチ | メリット | デメリット | 判定 |
|---|---|---|---|---|
| 1 | インスタンスごとの AuthorizedHttp | 公式推奨。変更が最小限。パイプライン内で接続を再利用 | リクエストごとに HTTP 接続を新規作成 | 採用 |
| 2 | Custom requestBuilder | 呼び出し側の変更不要 | API コールごとに新 HTTP(オーバーヘッド大) | 過剰 |
| 3 | コネクションプール | 接続を効率的に再利用 | プール管理・クリーンアップの複雑性 | 過剰 |
| 4 | httplib2 を requests/httpx に置換 | モダンでスレッドセーフ | google-api-python-client が httplib2 に密結合 | 非現実的 |
| 5 | Lock で直列化 | 最も単純な変更 | 全スレッドが直列実行になり並行性が消える | 却下 |
なぜ Approach 1(インスタンスごとの AuthorizedHttp)を選んだか
このボットでは、worker.py の process_message() が呼ばれるたびに新しい ChatApiClient() が生成されます。各 process_message() は独立したバックグラウンドスレッドで実行されるため、ChatApiClient インスタンスごとに独自の HTTP 接続を持たせれば、自然とスレッド間の分離が実現されるのです。
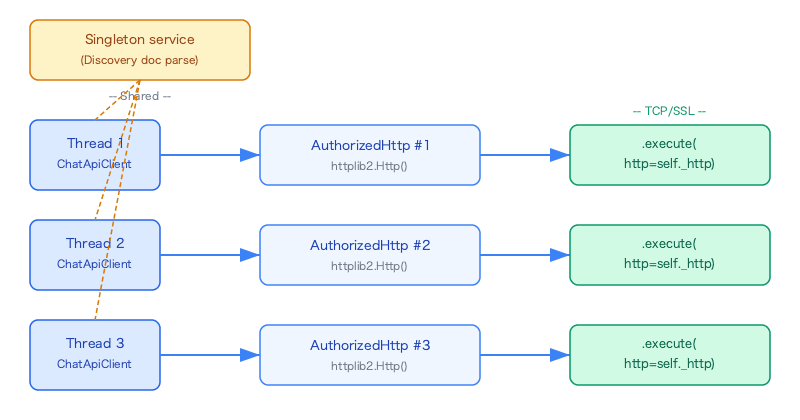
1つのパイプライン実行中(create 1回 + patch 数回)は同じ AuthorizedHttp を使い回すので、接続の再利用もできています。
コネクションプール(Approach 3)はDoIt のブログで紹介されていて魅力的でしたが、このボットの同時スレッド数は最大10程度。プール管理のコードを追加するほどの規模ではないと判断しました。
実装
変更は bot/chat_api.py の1ファイルのみです。新しい依存パッケージの追加もありません(google_auth_httplib2 と httplib2 は google-api-python-client の推移的依存として既にインストール済み)。
# bot/chat_api.py(修正後)
import google_auth_httplib2
import httplib2
_default_service = None
_credentials = None # 追加: 認証情報をモジュールレベルで保持
_lock = threading.Lock()
def _get_default_service():
global _default_service, _credentials
if _default_service is None:
with _lock:
if _default_service is None:
_credentials, _ = google.auth.default(scopes=SCOPES)
doc = json.loads(_DISCOVERY_DOC_PATH.read_text())
_default_service = build_from_document(doc, credentials=_credentials)
return _default_service
def _build_http():
"""インスタンスごとの独立した HTTP 接続を生成"""
return google_auth_httplib2.AuthorizedHttp(_credentials, http=httplib2.Http())
class ChatApiClient:
def __init__(self, service=None):
if service is None:
self._service = _get_default_service()
self._http = _build_http() # 各インスタンスが独自の HTTP 接続を持つ
else:
self._service = service
self._http = None # テスト用: mock service はそのまま使う
def create_message(self, space_name, body, thread_name=None):
# ... (省略)
response = (
self._service.spaces()
.messages()
.create(**kwargs)
.execute(http=self._http) # ← ここがポイント
)
return response["name"]
def patch_message(self, message_name, body, update_mask):
return (
self._service.spaces()
.messages()
.patch(name=message_name, updateMask=update_mask, body=body)
.execute(http=self._http) # ← ここも
)
テストへの影響
既存のテストは ChatApiClient(service=mock_service) のように mock を注入しています。この場合 self._http = None となり、.execute(http=None) は googleapiclient のデフォルト動作(service 内蔵の HTTP を使用)にフォールバックします。MagicMock は http=None を無視してそのまま return_value を返すので、98件のテストすべてが変更なしでパスしました。
検証
ローカルテスト
$ uv run pytest -v
============================= 98 passed in 1.05s ==============================
デプロイとスパムテスト
$ gcloud functions deploy google-chat-bot \
--gen2 --runtime=python314 --region=asia-northeast1 \
--source=. --entry-point=handle_chat --trigger-http \
--no-allow-unauthenticated --memory=2Gi --cpu=1
デプロイ後、Google Chat で10件のメッセージを数秒以内に連投。結果:
- 修正前: 10件中3〜5件がエラーカード
- 修正後: 10件すべて正常に回答を返却
ログ確認
$ gcloud functions logs read google-chat-bot \
--region=asia-northeast1 --gen2 --limit=50 \
--start-time="2026-06-15T06:31:00Z" \
| grep -iE "error|failed|SSLError|TimeoutError"
# 出力なし — エラーゼロ
まとめ
google-api-python-client を使ってマルチスレッドで API を呼び出す場合、httplib2.Http の共有は確実に壊れます。公式ドキュメントにも明記されていますが、シングルトンパターンで service を作ると自然と共有してしまうため、気づきにくい罠です。
対処法は .execute(http=...) に独立した AuthorizedHttp を渡すだけ。今回は ChatApiClient インスタンスごとに HTTP 接続を分離する方法を採用しましたが、規模に応じてコネクションプールも検討する価値があります。
同じ問題にハマった方の参考になれば幸いです。










