
【Copilot Studio】 集計用のKPIデータをエージェントに持たせる方法を比べてみた:チャット添付・ファイルナレッジ・SharePoint
はじめに
こんにちは、けーまです。
エージェントに数値を集計させるには、その前に「集計する元データをエージェントにどう渡すか」を決める必要があります。
いちばん手軽なのは、テストチャットにExcelを添付して集計させる方法です。
ただ、毎回ファイルを添付するのは、実際にエージェントを使う場面では手間です。
本当は、エージェントが最初からデータを持っていて、添付なしで「集計して」と頼むだけで動いてほしいところです。
そこで本記事では、集計用の構造化データ(Excel)をエージェントに渡す方法を取り上げ、2026年6月時点で実機検証しました。
チャット添付・ファイルのナレッジ・SharePoint の3つを比べ、特に「ファイルをナレッジに持たせるだけで、添付なしでコードインタープリターが集計できるか」を確かめます。
収集したデータをエージェントに恒久的に持たせて分析させたい方の参考にしていただければと思います。
本記事は、Copilot Studio でエージェントを作るシリーズの第5回です。
シリーズ全体では「収集 → 集計 → グラフ → 示唆 → 資料化」を一気通貫で行うエージェントを目指しており、本記事はその入口にあたる「収集」、つまり集計の前提となるデータの渡し方を扱います。
対象読者:Copilot Studio で、分析用のデータをエージェントに恒久的に持たせて集計させたい方
シリーズ記事一覧
| 回 | テーマ | 記事 |
|---|---|---|
| 第1回 | 最初のエージェント | 初めてのエージェントを作ってみた |
| 第2回 | ナレッジ | ナレッジでファイルに基づく回答を試してみた |
| 第3回 | トピック・ツール・フロー | トピック・ツール・エージェントフローで「動き」を作り込む |
| 第4回 | テンプレート・自律トリガー・マルチエージェント | テンプレート・自律トリガー・マルチエージェントで構成を広げてみた |
| 第5回 | 収集(データの渡し方) | (本記事) |
1. 今回やること
集計用の構造化データ(Excel)を、エージェントに渡す方法を比べます。
- データの渡し方を3経路で整理する(チャット添付・ファイルのナレッジ・SharePoint)
- ファイルをナレッジに追加するだけで、添付なしでコードインタープリターが集計できるかを試す
- 公式が示す正攻法(SharePoint + Work IQ)を実機で試し、公開しなくてもテストできるかを確かめる
検証には、これまでと同じ架空の SaaS 企業3社(CloudNova / StreamForge / Datapeak)の月次 KPI データ(架空)を使います。
2. なぜ「データの渡し方」が論点になるのか
コードインタープリターでKPIを集計するには、集計対象のExcelをエージェントに与える必要があります。
このとき、与え方によって「使うたびに手で渡すのか」「最初から持っているのか」が変わります。
公式ドキュメントは、コードインタープリターが構造化データを取り込む方法を次の2つに整理しています。
Copilot Studio agents can use code interpreter to analyze structured files that are provided to the agent by the following two ways:
- As an end-user, when you upload structured files while chatting with the agent.
- As a maker, when you add SharePoint Documents library as a knowledge source, which in turn contains the structured files.
引用元: Use code interpreter to analyze structured data (preview) | Microsoft Learn
本記事では、この公式ドキュメント記載の手段である「チャット添付(本稿の 経路A)」および「SharePoint(本稿の 経路C)」に加えて、もっと手軽にExcelファイルをエージェントに直接アップロードする「ファイルの直接ナレッジ化(本稿の 経路B)」でも集計可能かを試します。
3. データの渡し方3経路
エージェントに集計用Excelを渡す方法を、本記事では次の3つで比べます。
3つのデータ経路における各構成要素(チャット・Dataverse・SharePoint)とエージェント間のデータ取得フローのイメージ
| 経路 | 渡し方 | データの持ち方 | 公式ドキュメントでの記載 | 向くケース |
|---|---|---|---|---|
| A:チャット添付 | 会話のたびにExcelを添付 | 一時的(その会話だけ) | エンドユーザー添付として公式に対応 | その場限りの分析・アドホックな質問 |
| B:ファイルのナレッジ | Excelをファイルとしてアップロードしナレッジ化 | 恒久的(エージェントが保持) | 直接アップロードによる集計は公式明記なし(本稿独自検証) | 添付なしで毎回同じデータを集計させたい |
| C:SharePoint(Work IQ) | SharePoint の Documents ライブラリをナレッジにし Work IQ を有効化 | 恒久的(SharePointと同期) | SharePointドキュメント連携として公式に対応 | 大きいデータ・最新へ同期・権限制御が要る |
本記事では、この3経路をすべて実機で確かめます。
まず手軽な経路A(チャット添付)から始め、続いて経路B(ファイルのナレッジ)、公式が正攻法として示す経路C(SharePoint + Work IQ)の順に見ます。
4. 経路A:チャット添付で集計させる
経路Aは、いちばん手軽な渡し方です。
会話のたびにExcelを添付して、その場で集計させます。
公式がコードインタープリターの構造化データ入力として明記している「エンドユーザーによる会話中のファイルアップロード」に相当します。
As an end-user, when you upload structured files while chatting with the agent.
引用元: Use code interpreter to analyze structured data (preview) | Microsoft Learn
4.1 検証用のExcelを用意する
本記事の3経路(A・B・C)すべてで、この同じExcelを使います。
前年比(YoY)を出すため、前年同期のデータが要ります。
3社×(2024年・2025年の各10〜12月)の月次KPIを、1つの RawMonthly シートに持つExcelを用意します。
集計はコードインタープリターに任せるので、このファイルには集計用の数式やサマリーは入れず、生データだけを持たせます。
検証用Excelの生成スクリプト(クリックすると展開します)
#!/usr/bin/env python3
"""前年比(YoY)集計の検証用Excelを生成する。
コードインタープリター(CI)に読ませる生データ。
3社×(2024年・2025年の各10〜12月)の月次KPIを1つのRawMonthlyシートに持つ。
集計(合計・平均・前年比)はCIのPython(pandas)で決定論的に行う前提のため、
このファイルには集計用の数式やサマリーシートは入れない(生データだけを渡す)。
"""
from openpyxl import Workbook
from openpyxl.worksheet.table import Table, TableStyleInfo
OUT = "kpi-raw-data-yoy.xlsx"
# 生データ(架空)。2024年の10〜12月は成長前の低めの値、2025年の10〜12月は前年から伸びた値。
# (会社, 月, ARR(百万円), NRR(%), 営業利益率(%))
RAW = [
("CloudNova", "2024-10", 1600, 116, 11),
("CloudNova", "2024-11", 1625, 117, 11.5),
("CloudNova", "2024-12", 1650, 118, 12),
("StreamForge", "2024-10", 1160, 105, -1),
("StreamForge", "2024-11", 1180, 106, -0.5),
("StreamForge", "2024-12", 1200, 107, 0),
("Datapeak", "2024-10", 2450, 124, 16.5),
("Datapeak", "2024-11", 2500, 125, 17),
("Datapeak", "2024-12", 2550, 126, 17.5),
("CloudNova", "2025-10", 1900, 119, 13),
("CloudNova", "2025-11", 1950, 120, 13.5),
("CloudNova", "2025-12", 2000, 121, 14),
("StreamForge", "2025-10", 1280, 108, 0.5),
("StreamForge", "2025-11", 1300, 109, 1),
("StreamForge", "2025-12", 1320, 110, 1.5),
("Datapeak", "2025-10", 2750, 127, 18.5),
("Datapeak", "2025-11", 2800, 128, 19),
("Datapeak", "2025-12", 2880, 129, 19.5),
]
def main() -> None:
wb = Workbook()
ws = wb.active
ws.title = "RawMonthly"
ws.append(["Company", "Month", "ARR", "NRR", "OPM"])
for row in RAW:
ws.append(list(row))
table = Table(displayName="RawMonthly", ref=f"A1:E{len(RAW) + 1}")
table.tableStyleInfo = TableStyleInfo(
name="TableStyleMedium2", showRowStripes=True
)
ws.add_table(table)
wb.save(OUT)
print(f"saved {OUT}")
if __name__ == "__main__":
main()
このスクリプトを make_excel_yoy.py として保存し、次のコマンドで実行します(openpyxl が必要です)。
pip install openpyxl
python make_excel_yoy.py
# 出力例
saved kpi-raw-data-yoy.xlsx
できあがる RawMonthly シートは、3社×2年×3か月(10〜12月)の18行です。
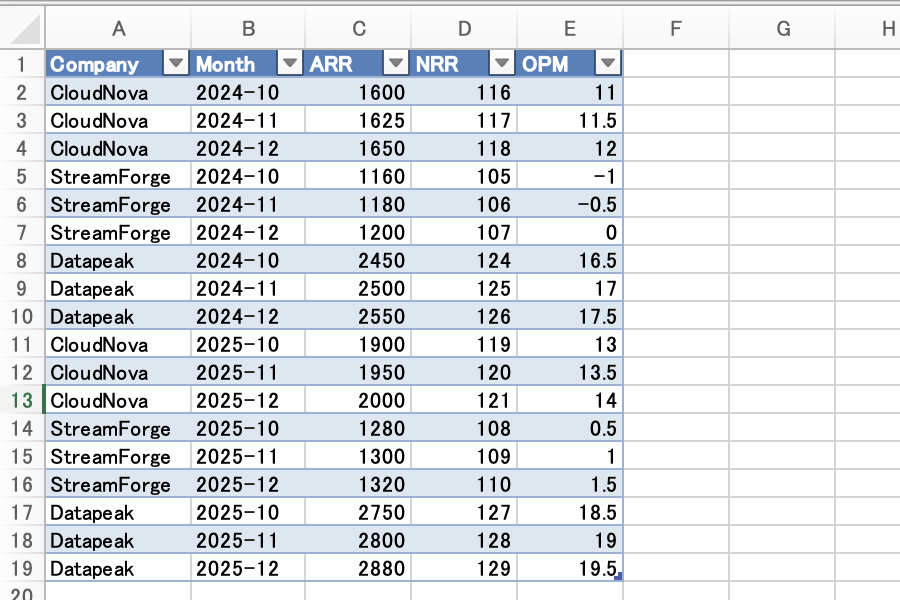
生成した kpi-raw-data-yoy.xlsx の RawMonthly シート。Company・Month・ARR・NRR・OPM の5列に、3社×2024/2025年 10〜12月の生データ(18行)が入っている
このファイルをコードインタープリターに集計させたとき、結果が次の値になれば「正しく集計できた」と判断します(合格基準)。
丸めは ARR・NRR が0桁、営業利益率(OPM)が1桁、前年比が1桁です。
| 会社 | 2024 ARR平均 | 2024 NRR平均 | 2024 OPM平均 | 2025 ARR平均 | 2025 NRR平均 | 2025 OPM平均 | ARR前年比 |
|---|---|---|---|---|---|---|---|
| CloudNova | 1625 | 117 | 11.5 | 1950 | 120 | 13.5 | +20.0% |
| StreamForge | 1180 | 106 | -0.5 | 1300 | 109 | 1.0 | +10.2% |
| Datapeak | 2500 | 125 | 17.0 | 2810 | 128 | 19.0 | +12.4% |
各値の計算方法は次のとおりです。
- ARR平均・NRR平均・OPM平均:その年の10〜12月の3か月を単純平均する(2024年・2025年とも同じ)。たとえば CloudNova の 2025年 NRR平均は (119 + 120 + 121) ÷ 3 = 120、2025年 OPM平均は (13 + 13.5 + 14) ÷ 3 = 13.5。2024年も同様に、NRR平均 (116 + 117 + 118) ÷ 3 = 117、OPM平均 (11 + 11.5 + 12) ÷ 3 = 11.5。
- ARR前年比(YoY):(2025年ARR平均 ÷ 2024年ARR平均 − 1) × 100。CloudNova なら 2025年ARR平均 (1900 + 1950 + 2000) ÷ 3 = 1950、2024年ARR平均 (1600 + 1625 + 1650) ÷ 3 = 1625 なので、(1950 ÷ 1625 − 1) × 100 = +20.0%。
4.2 チャットに添付して集計を依頼する
テストチャットの入力欄にある 「ファイルのアップロード」 から kpi-raw-data-yoy.xlsx を添付し、集計の依頼文を送ります。
添付したExcel(RawMonthlyシート)を、コードインタープリター(Python/pandas)で集計してください。会社(CloudNova / StreamForge / Datapeak)ごとに、2024年と2025年それぞれのARR平均・NRR平均・OPM平均を出し、ARRの前年比(YoY%)も計算してください。丸めはARRとNRRは整数(0桁)、OPMは小数1桁、前年比は小数1桁。LLMの推論ではなくPythonコードで計算してください。
私の環境では、エージェントが添付ファイルの RawMonthly シート(18行)をコードインタープリターで読み込み、Pythonで集計しました。
集計結果は、4.1 の合格基準と一致しました(CloudNova の ARR前年比 +20.0%、StreamForge +10.2%、Datapeak +12.4%、NRR・OPM もすべて一致)。
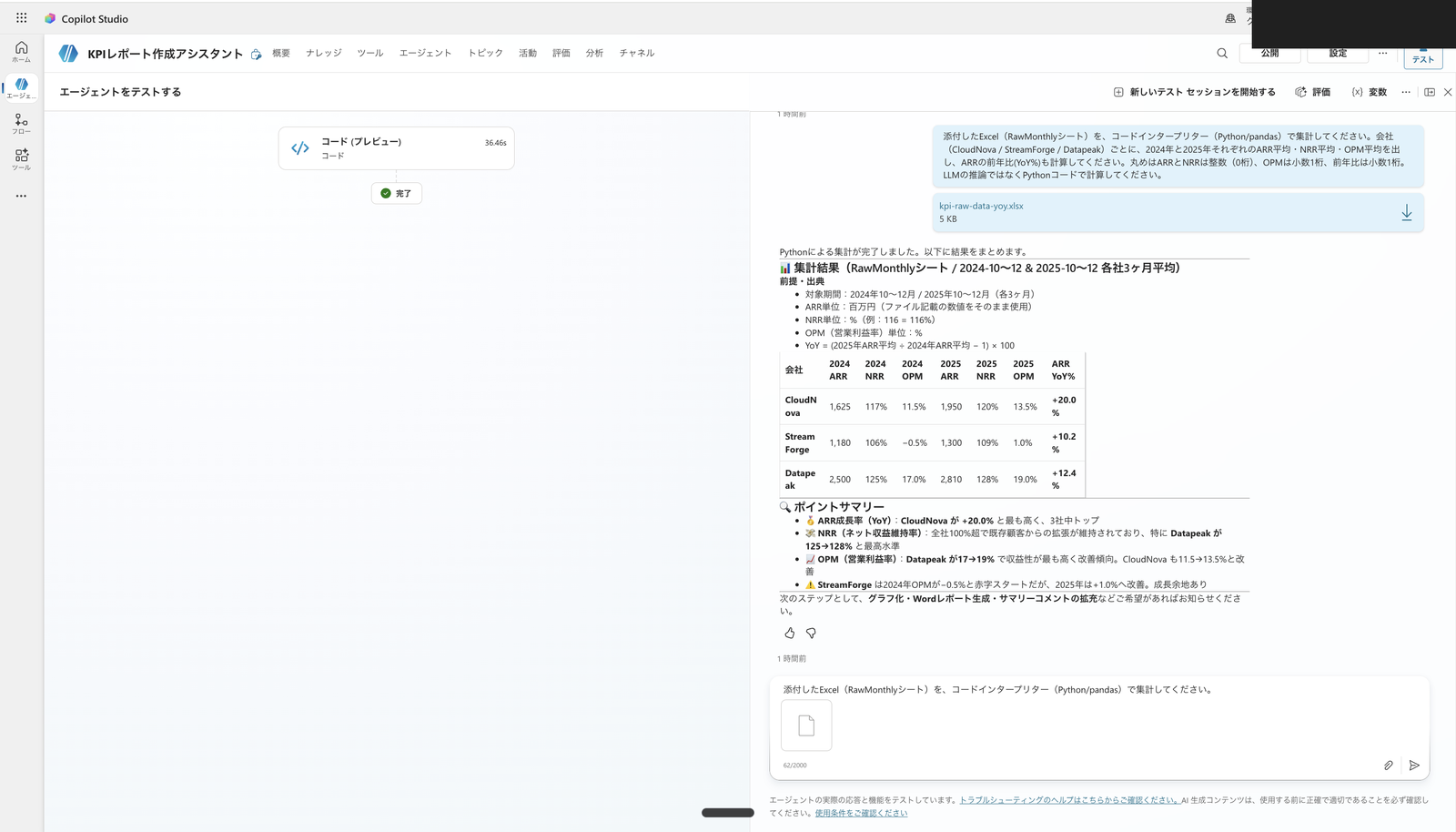
テストの全体。右上で kpi-raw-data-yoy.xlsx を添付して集計を依頼し、左の活動マップで「コード(プレビュー)」が完了(実行時間36.46秒)、右に会社×年のARR・NRR・OPM平均と前年比が合格基準どおりに返っている
経路Aは手軽ですが、会話のたびに添付が要ります。
添付なしで毎回同じデータを集計させたいなら、次の経路B(ファイルのナレッジ)が向きます。
5. 経路B:ファイルのナレッジに持たせて集計させる
5.1 検証のねらい
公式がコードインタープリターの構造化データ入力としてサポートしているのは、チャット添付(本稿の 経路A)と、SharePointのドキュメントライブラリ接続(本稿の 経路C)の2つのルートです。
ファイルを直接「アップロードしてナレッジにする」選択肢(本稿の 経路B)は、これらに含まれていません。
そこで、ファイルのナレッジに Excel を入れただけで、チャットに添付せずにコードインタープリターが集計に使えるかを実機で確かめます。
なお、アップロードしたファイルは Dataverse に格納され、インデックス化されてナレッジになります。
Files uploaded in Copilot Studio use Microsoft Dataverse to ingest raw files and create indexes and vector embeddings.
引用元: Unstructured data as a knowledge source | Microsoft Learn
5.2 Excelをファイルのナレッジに追加する
使うExcelは、経路Aの 4.1 で用意した kpi-raw-data-yoy.xlsx(同じファイル)です。
エージェントの 「ナレッジ」 ページ(または概要ページ)から 「ナレッジの追加」 を開き、ファイルのアップロードで kpi-raw-data-yoy.xlsx を追加します。
ナレッジには名前と説明を付けます。
説明は、生成オーケストレーションがこのナレッジを選ぶ手がかりになるため、何のデータかが分かるように書きます。
The description should be detailed, especially if generative AI is enabled, because it helps generative orchestration.
引用元: Upload files as a knowledge source | Microsoft Learn
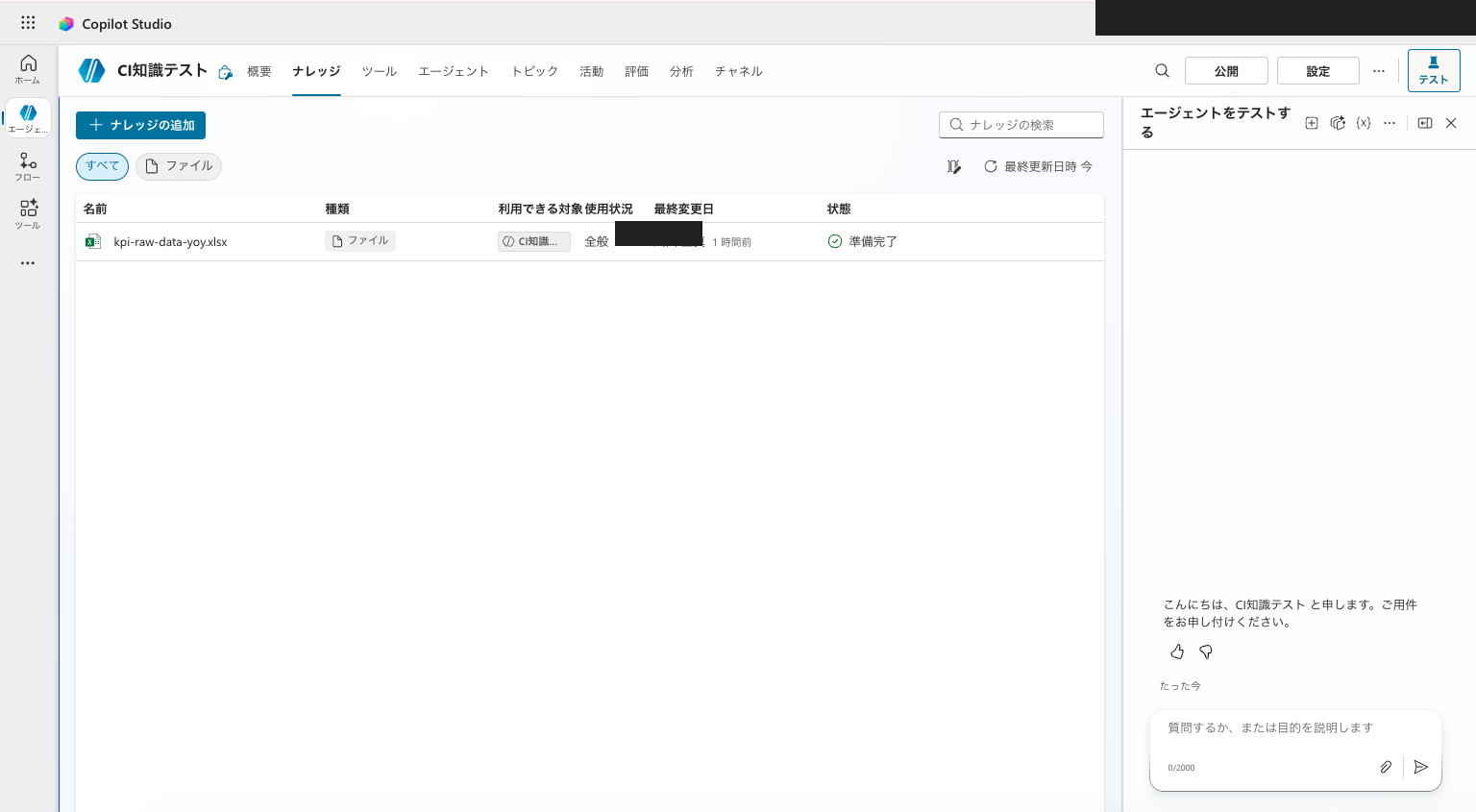
kpi-raw-data-yoy.xlsx をファイルのナレッジとして追加し、インデックス化が完了した状態。これでエージェントが添付なしでこのデータを参照できる
5.3 コードインタープリターを有効化する
コードインタープリターは環境ごとに有効化が必要で、初期値はオフです。
エージェントの 「設定」→「生成AI」 の 「ファイルの処理能力」 で、「コードインタープリター」 をオンにします。
- In Copilot Studio, select Settings > Generative AI. Under File processing capabilities, turn on the File uploads toggle.
- Under File processing capabilities, turn on the Code interpreter toggle.
- Select Save.
引用元: Use code interpreter to analyze structured data (preview) | Microsoft Learn
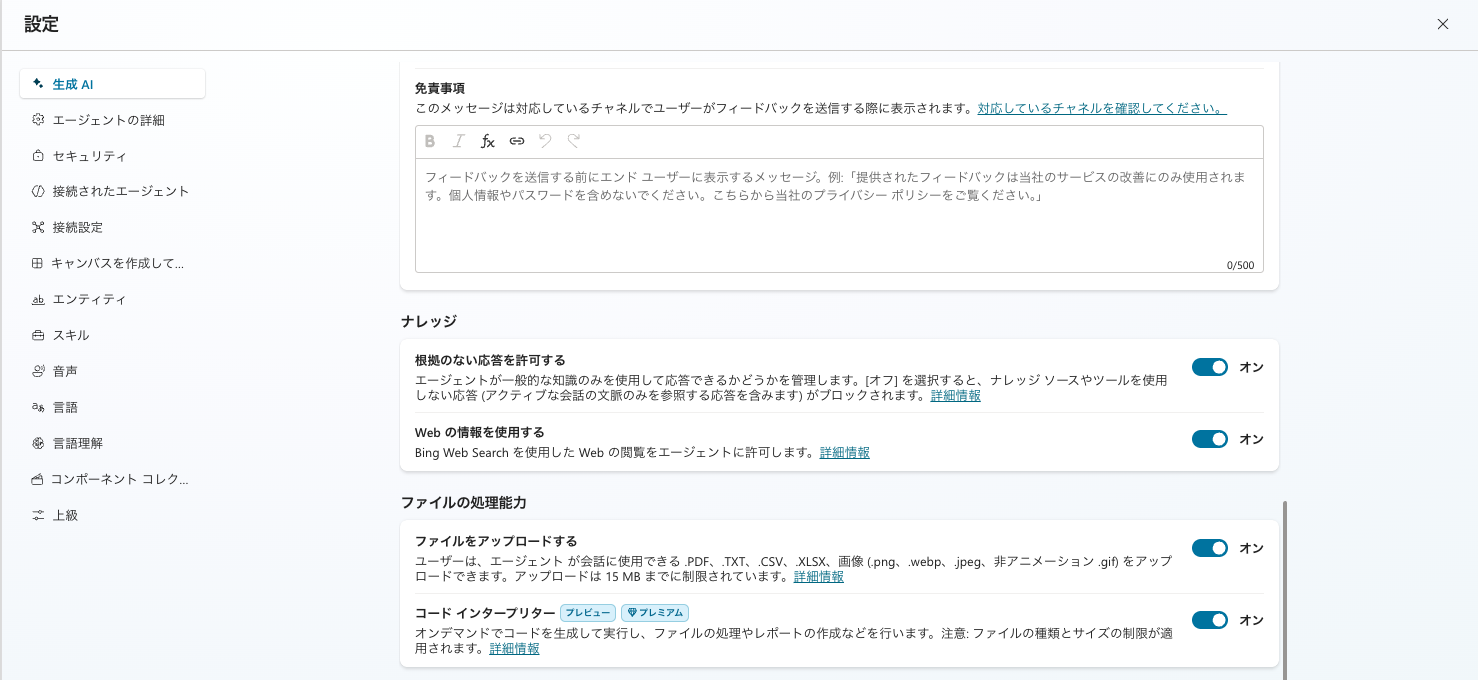
「設定」→「生成AI」→「ファイルの処理能力」で「コードインタープリター」をオンにする。私の環境では「ファイルをアップロードする」とあわせて有効になっていた
5.4 添付せずに集計を依頼する
テストチャットで、ファイルを添付せず、ナレッジにあるデータを集計するよう依頼します。
ナレッジにあるKPIのExcel(RawMonthlyシート)を、コードインタープリター(Python/pandas)で集計してください。会社(CloudNova / StreamForge / Datapeak)ごとに、2024年と2025年それぞれのARR平均・NRR平均・OPM平均を出し、ARRの前年比(YoY%)も計算してください。丸めはARRとNRRは整数(0桁)、OPMは小数1桁、前年比は小数1桁。LLMの推論ではなくPythonコードで計算してください。
私の環境では、エージェントはまずナレッジからデータを取得し、続けてコードインタープリターでPythonを実行しました。
集計結果は、4.1 の合格基準と一致しました(CloudNova の ARR前年比 +20.0%、Datapeak +12.4%、StreamForge +10.2%、NRR・OPM もすべて一致)。
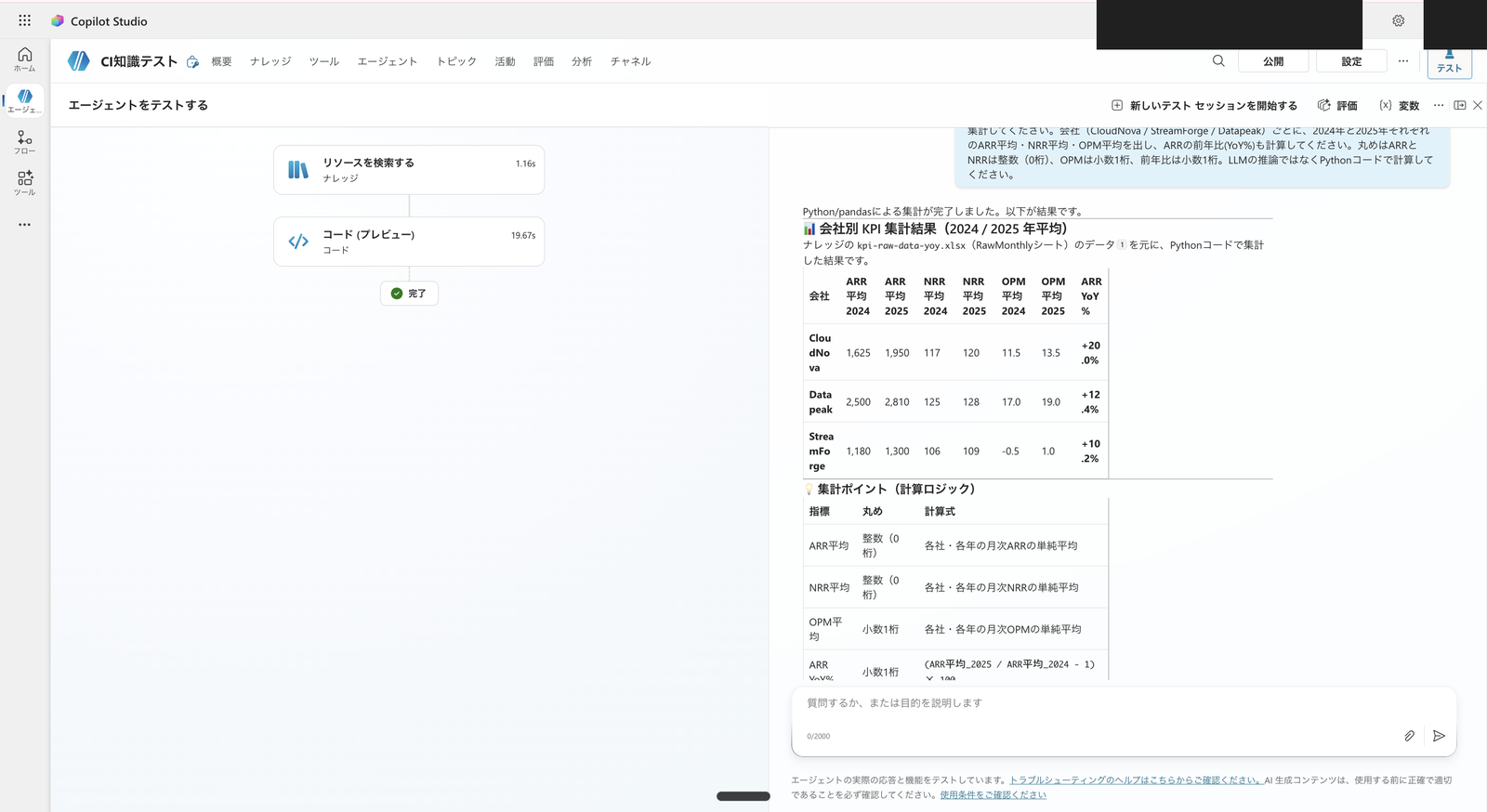
添付なしで「ナレッジのKPIを集計して」と依頼した結果。エージェントが「ナレッジからデータを取得し、Pythonで集計する」と示し、会社×年のARR・NRR・OPM平均と前年比が合格基準どおりに返ってきた
チャットへの添付も SharePoint の用意もなしで、エージェントが自分の持っているデータをコードインタープリターで集計できました。
分析を担うエージェントにデータを恒久的に持たせる、という観点では、ファイルのナレッジが一番手軽な選択肢になります。
5.5 経路Bの注意点(公式保証の範囲)
経路Bは手軽ですが、押さえておくべき前提があります。
1つ目は、これが公式に明記された経路ではないことです。
2章のとおり、公式がコードインタープリターの構造化データ入力として挙げているのは、チャット添付と SharePoint Documents ライブラリの2つです。
ファイルのナレッジで動いたのは私の環境での実機結果であり、公式に保証された方法ではありません。
確実性が要る本番では、次章の経路C(SharePoint + Work IQ)を検討してください。
2つ目は、データの渡り方です。
私の環境では、ナレッジ検索がExcelの中身をテキストとして返し、コードインタープリターがそれをコード内のデータとして取り込んで集計していました。
今回のような小さい表なら全行が入りますが、行数が多いデータでは、ナレッジ検索が一部しか返さず取りこぼす恐れがあります。
大きいデータや、全件を確実に集計したい場合は、経路Cが堅実です。
3つ目は、ファイルの更新です。
ファイルのアップロードは静的で、元ファイルを更新しても自動では反映されません。手動で入れ直す必要があります。
In the upload files method, files are static. So, if the file is updated, those updates aren't reflected in the uploaded version unless manually updated.
引用元: Add unstructured data as a knowledge source | Microsoft Learn
6. 経路C:SharePoint(Work IQ)で持たせて集計させる
データが大きい、最新に同期したい、利用者ごとに権限を効かせたい、という場合は、公式が正攻法として示す SharePoint 経由が向きます。
6.1 経路Bとの違い
経路C(SharePoint コネクタ)と経路B(ファイルのアップロード)では、データの保存先・鮮度・権限の扱いが異なります。
保存先と鮮度です。
経路Cはデータを SharePoint に残したまま参照し、最新の内容をリアルタイムに反映します。
公式は、SharePoint をナレッジにする2つのオプション(ファイルのアップロード経由=オプション1/SharePoint コネクタ=オプション2)を比べており、経路Cはこのオプション2にあたります。
Scenario Option 1: file upload Option 2: SharePoint connector Content storage Copied into Dataverse from SharePoint Resides in SharePoint Content freshness Content is synchronized every four to six hours, based on ingestion completion Real time, and reflects the latest available content Dataverse storage consumption Yes, for copied files and search indexes No
引用元: Unstructured data as a knowledge source | Microsoft Learn
一方、本記事の経路B(ローカルExcelのファイルのアップロード)は、Dataverse にコピーして保存する静的な持ち方です。
元ファイルを更新しても、手動で入れ直すまで反映されません(5.5 参照)。
権限の確認の仕方も違います。
コネクタ経由(経路C)は、利用者がクエリするたびに、その人の資格情報でアクセス権をライブ確認してから回答します。
When a user makes a query, the system uses their connection information to check the data source and verify they have permission to see the content. Even though the system stores chunks and indexes locally in Dataverse, it performs a live check on the queries to make sure the current user has access to the data before providing a summary or response.
引用元: Unstructured data as a knowledge source | Microsoft Learn
6.2 ナレッジに「SharePoint」を追加する
まず、集計対象の Excel(経路Bと同じ kpi-raw-data-yoy.xlsx)を SharePoint のドキュメントライブラリに置きます。
次に、エージェントの 「ナレッジ」→「ナレッジの追加」 を開きます。
ここで注意点があります。
「ナレッジの追加」ダイアログには、SharePoint の入口が2か所あります。
- 上部「ファイルのアップロード」内の「SharePoint」:SharePoint 上の個々のファイル・フォルダーを選んで Dataverse にコピーする方法です。コードインタープリターで使うドキュメント ライブラリには対応していません。
- おすすめセクションの「SharePoint」:SharePoint コネクタによるフル統合です。構造化データのコードインタープリターで使うのは、こちらのおすすめセクションにある方です。
The SharePoint option in the file upload section is for uploading individual SharePoint files or folders to your agent. This option uploads a copy of the file from SharePoint to Dataverse and maintains a synchronous relationship to keep the file up to date.
The other SharePoint option provides the full SharePoint integration in Copilot Studio using the SharePoint connector. Use this option when you need full SharePoint connector capabilities, custom authentication configurations, or advanced query options.
引用元: Unstructured data as a knowledge source | Microsoft Learn
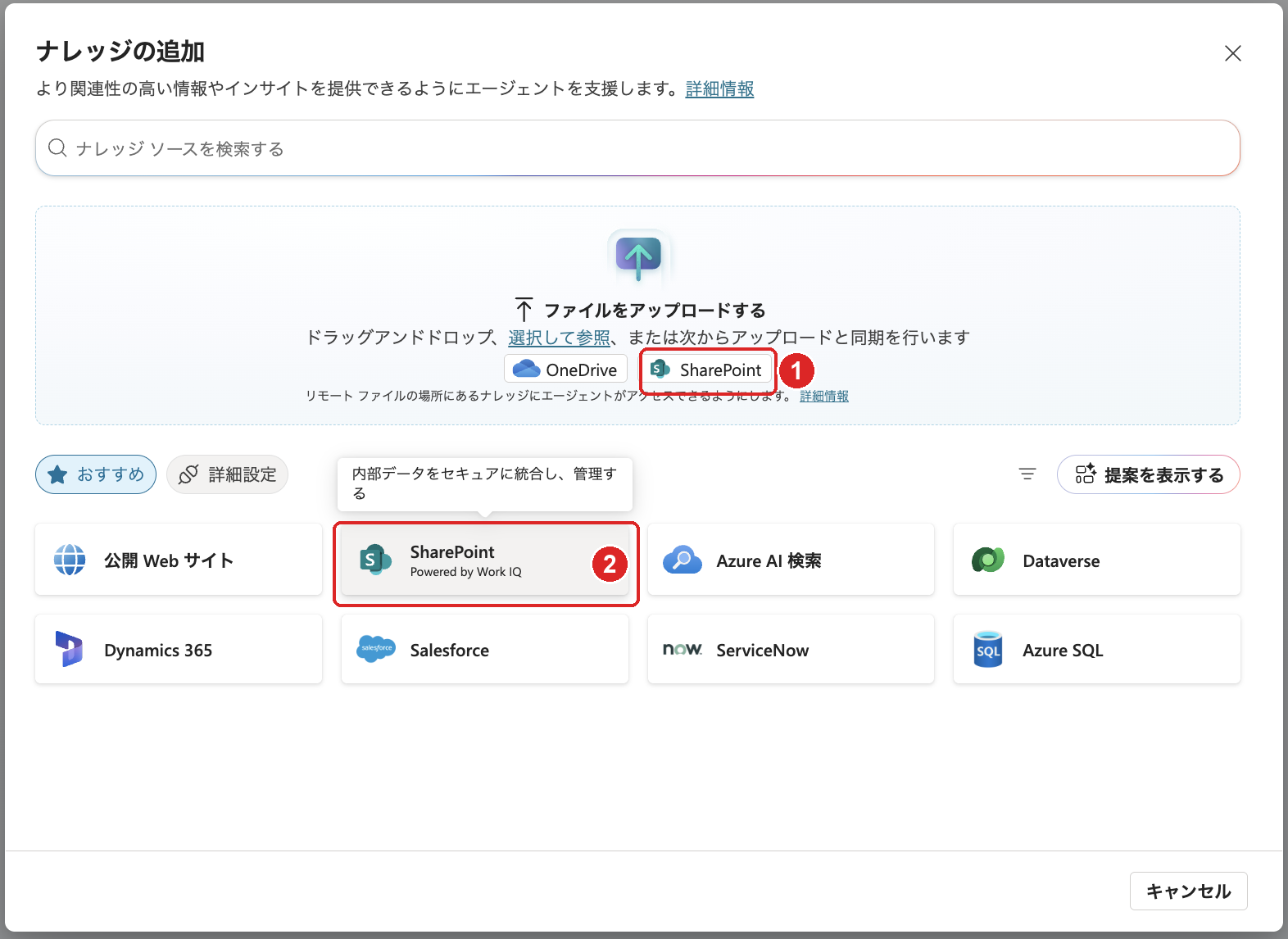
「ナレッジの追加」にある2つの SharePoint。上部は「ファイルのアップロード」内(Dataverse へコピー・ドキュメント ライブラリ非対応)、下部はおすすめセクションの SharePoint コネクタ。コードインタープリターで使うのは下部のおすすめセクション
SharePoint のサイト(またはドキュメント ライブラリ)のURLを入れ、名前と説明を付けて追加します。
追加後、ナレッジ一覧にSharePointソースが「準備完了」で表示されれば、エージェントがこのデータを参照できます。
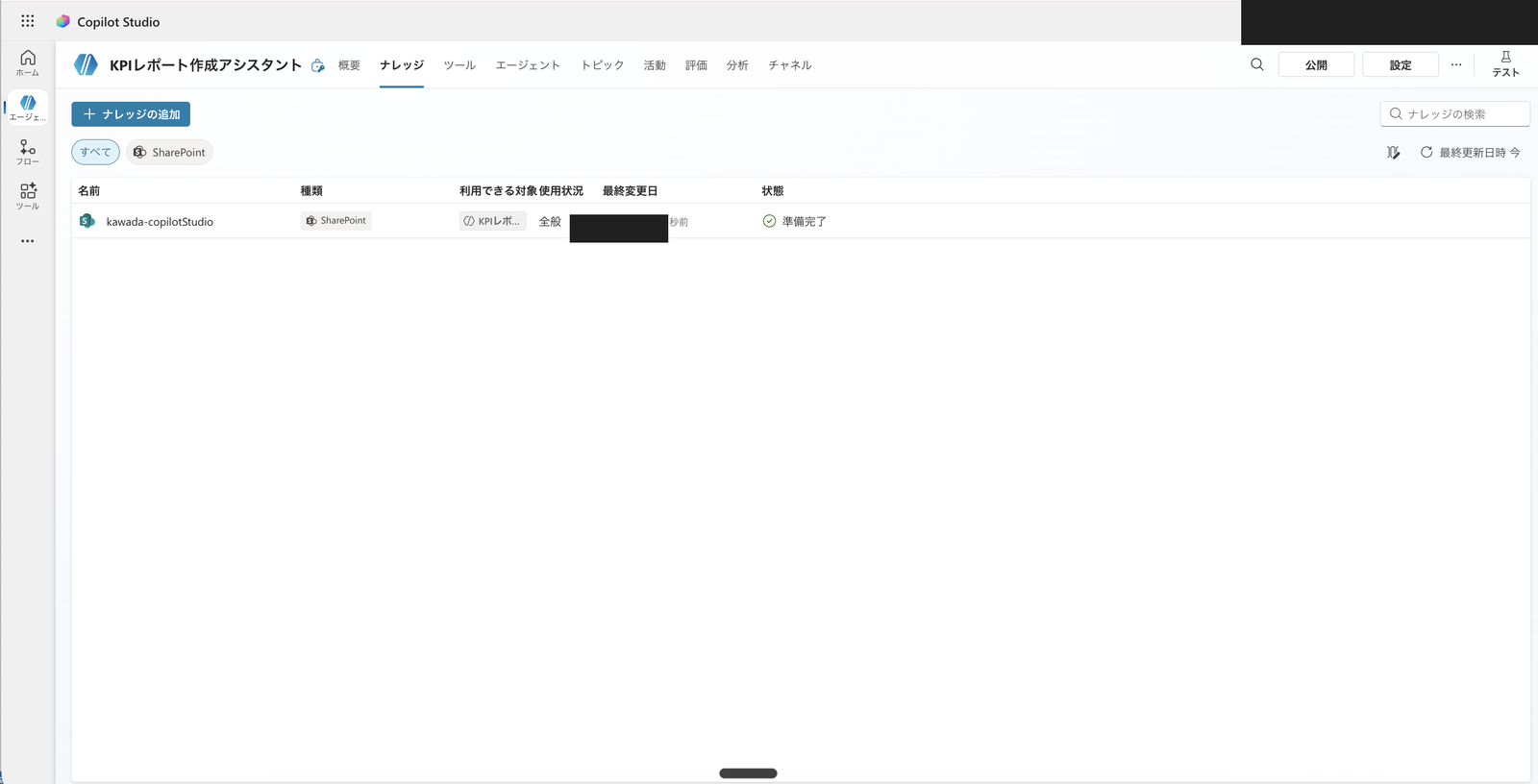
SharePoint のドキュメント ライブラリをナレッジに追加し、状態が「準備完了」になった状態。右上に「公開」ボタンが残っており、まだ公開していないことが分かる
6.3 Work IQ をオンにする
コードインタープリターは 5.3 でオンにしました。
経路Cでは、これに加えて Work IQ をオンにします。
公式の手順は、SharePoint をナレッジに追加し、コードインタープリターと Work IQ をオンにして保存、公開してからテスト、という流れです。
- If your agent doesn't already have a SharePoint structured data file as a knowledge source, add this SharePoint file as a knowledge source.
- In Copilot Studio, select Settings > Generative AI. Under File processing capabilities, turn on the Code interpreter toggle.
- Under Search, select Turn on Work IQ.
- Select Save.
- If you added a SharePoint file following instructions in the first step, publish your agent.
- Test your agent by giving it a query that requires the agent to do a computation in order to answer.
引用元: Use code interpreter to analyze structured data (preview) | Microsoft Learn
実機では、「設定」→「生成AI」 の 「検索」 で 「セマンティック検索を使用したテナント グラフの根拠」 をオンにして保存します。
公式の「Turn on Work IQ」は、日本語UIではこの「セマンティック検索を使用したテナント グラフの根拠」に当たります。
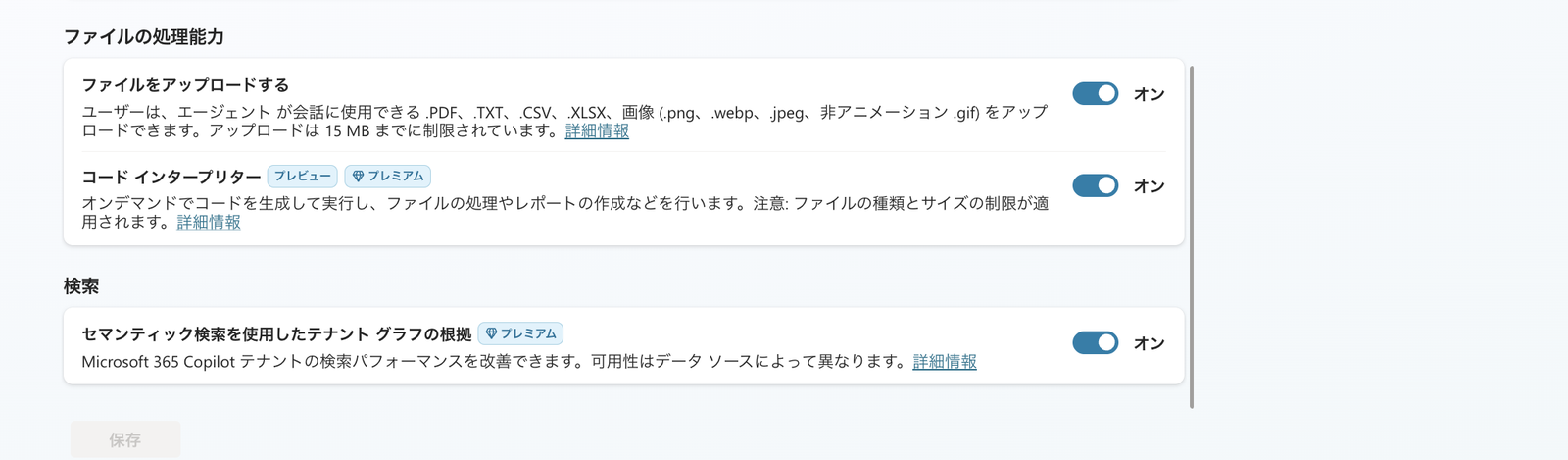
「ファイルの処理能力」でコードインタープリター、「検索」でセマンティック検索を使用したテナント グラフの根拠(=Work IQ)をオンにする
6.4 公開せずにテストする
公式手順はステップ5で「エージェントを公開する」を挟みます。
ただし、これは手順の一段であって、「公開しないとテストできない」とは書かれていません。
テストパネルは、公開版ではなく保存した下書きを反映します。
The Test agent pane automatically refreshes when you select Save after editing your topics.
引用元: Quickstart guide for building agents with generative AI | Microsoft Learn
そこで、公開せず(右上の「公開」ボタンを押さないまま)、テストパネルで経路Bと同じ集計を依頼しました。
ナレッジにあるSharePointのKPI Excel(RawMonthlyシート)を、コードインタープリター(Python/pandas)で集計してください。会社(CloudNova / StreamForge / Datapeak)ごとに、2024年と2025年それぞれのARR平均・NRR平均・OPM平均を出し、ARRの前年比(YoY%)も計算してください。丸めはARRとNRRは整数(0桁)、OPMは小数1桁、前年比は小数1桁。LLMの推論ではなくPythonコードで計算してください。
公開していない状態でも、エージェントはSharePointのナレッジからデータを取得し、続けてコードインタープリターでPythonを実行しました。
集計結果は、4.1 の合格基準と一致しました(CloudNova の ARR前年比 +20.0%、Datapeak +12.4%、StreamForge +10.2%、NRR・OPM もすべて一致)。
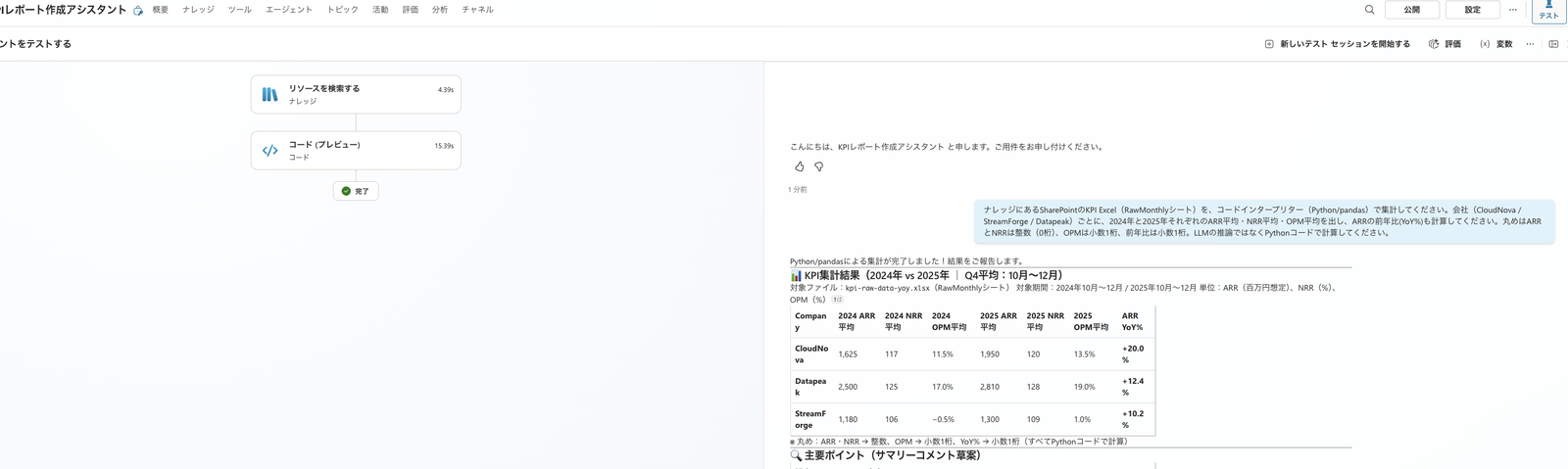
公開しないまま、テストパネルで集計を依頼した結果。左のトレースに「リソースを検索する(ナレッジ取得)」→「コード(コードインタープリター実行)」が出ており、SharePointのExcelを取得してPythonで集計し、合格基準どおりの数値が返っている
7. マルチエージェントで分析サブにデータを持たせる
最終ゴールの一気通貫エージェントは、窓口となる親エージェントと、工程ごとのサブエージェントに分ける構成を想定しています。
このとき、集計を担う「分析サブ」にデータをどう持たせるかが論点になります。
ここで効いてくるのが、親エージェントが子エージェントを呼ぶとき、自動で引き継がれるのは会話の履歴だけという公式仕様です。
Copilot Studio passes along the conversation history by default when one agent calls another, so the connected agent knows what's already been discussed.
引用元: Explore multi-agent orchestration patterns | Microsoft Learn
そのため、親に添付したファイルが自動でそのまま分析サブに渡る前提では設計できません(追加データの受け渡しは本記事では未検証です)。
分析サブが集計するには、サブ自身がデータを持っている必要があります。
本記事で確かめたとおり、ファイルのナレッジ(経路B)か SharePoint(経路C)でサブにデータを持たせておけば、親から委譲されたときにサブが自分のデータを集計できる、という設計になります。
8. 3経路の使い分け
実機で確かめた結果、データの渡し方は次のように整理できます。
- その場限りの分析なら経路A(チャット添付)。会話のたびに渡すぶん、恒久的に持たせる設定は不要です。
- 添付なしで毎回同じデータを集計させたいなら経路B(ファイルのナレッジ)。一番手軽で、小さいデータなら添付なしでコードインタープリターが集計できました。ただし公式保証の経路ではなく、大きいデータでは取りこぼす恐れがあります。
- 大きいデータ・最新への同期・権限制御が要るなら経路C(SharePoint + Work IQ)。公式が正攻法として示す方法で、本番向きです。公開は本番チャネルへの配信に必要ですが、テストパネルでの動作確認は公開せずに行えました。
分析サブにデータを持たせる現実解は、データの規模と確実性で B と C を選ぶ、という整理になります。
まとめ
集計の手前にある「データの渡し方」を、3つの経路で比べました。
- コードインタープリターの公式入力はチャット添付と SharePoint Documents の2つ
- ファイルのナレッジ(経路B)でも、添付なしでコードインタープリターが集計できた(小さいデータ・公式保証外)
- 大きいデータや同期・権限が要るなら SharePoint + Work IQ(経路C)が正攻法。私の環境では、公開しなくてもテストパネルで集計できた
- 親エージェントが子エージェントを呼ぶとき、自動で引き継がれるのは会話の履歴。集計を担う子エージェントには、データをあらかじめ自前のナレッジで持たせておくのが安全(添付ファイルの自動引き継ぎは本記事では未検証)
参考
- Use code interpreter to analyze structured data (preview) | Microsoft Learn
- Upload files as a knowledge source | Microsoft Learn
- Add unstructured data as a knowledge source | Microsoft Learn
- Unstructured data as a knowledge source | Microsoft Learn
- Explore multi-agent orchestration patterns | Microsoft Learn
- FAQ for Copilot Studio billing and licensing | Microsoft Learn









