
Cloudflare AI SearchにDevelopersIOのブログ記事を食わせて、自然言語で検索できるか試してみた
ベルリンオフィスの小西です。
CloudflareがAI Searchというマネージド検索サービスをリリースしました(現在オープンベータ)。コンテンツを渡すと、チャンク分割・ベクトル化・インデックス構築を自動でやってくれて、自然言語で検索できるようになります。
弊社の本ブログ DevelopersIO の記事は約6万件をContentfulで管理しています。今回はこの一部をAI Searchに食わせてみました。セットアップから日本語での検索精度まで試した内容をまとめます。
Cloudflare AI Searchとは
コンテンツをアップロードまたはクロールさせると、チャンク分割・ベクトル化・インデックス構築をやってくれるマネージドサービスです。
特徴:
- データソースは3種類: Webサイトクロール、R2バケット、Items APIによる直接アップロード
- ハイブリッド検索に対応: ベクトル(セマンティック)検索とBM25キーワード検索を並列で実行し、結果をマージしてくれる
- 検索インターフェース: Wrangler CLI、REST API、Workers binding、MCPサーバーから叩ける
- 料金: ベータ期間中は制限内なら無料(Workers AIとAI Gatewayの利用分は別途課金)
今回やったこと
DevIOのバックエンドから記事を取得して、AI Searchに流し込み、自然言語で検索できるようにします。
使ったもの:
- Cloudflareアカウント(Free plan)
- Wrangler CLI
- Node.jsスクリプト(データ取得・アップロード用)
- ※今回Node.jsスクリプトの詳細については割愛します。
AI Searchインスタンスのセットアップ
まずはWrangler CLIでインスタンスを作ります。ダッシュボードやREST APIからも可能です。
$ wrangler ai-search create devio-search
対話形式でいくつか聞かれます。今回はCMSからローカル経由でItems APIでデータを直接アップロードするため、ソースタイプは Builtin(Cloudflare管理のストレージ)を選択。
✔ Select the source type: › Builtin
✔ Configure custom metadata fields? (optional) … no
Creating AI Search instance "devio-search" in namespace "konishi-test"...
Successfully created AI Search instance "devio-search"
Name: devio-search
Namespace: konishi-test
Type: builtin
Source: -
Model:
Embedding: @cf/qwen/qwen3-embedding-0.6b
エンベディングモデルは @cf/qwen/qwen3-embedding-0.6b が自動で割り当てられました。
状態を stats で確認します。
$ wrangler ai-search stats devio-search --namespace konishi-test
┌────────┬────────────┬─────────┬─────────┬──────────┬────────┐
│ Queued │ Processing │ Indexed │ Skipped │ Outdated │ Errors │
├────────┼────────────┼─────────┼─────────┼──────────┼────────┤
│ 0 │ 0 │ 0 │ 0 │ 0 │ 0 │
└────────┴────────────┴─────────┴─────────┴──────────┴────────┘
作成直後なので全部ゼロ。--namespace はインスタンス作成時に指定した namespace 名を渡してください。
メタデータについて
AI Searchでは、インデックスされたドキュメントにメタデータを付与できます。メタデータは結果のフィルタリングやランキング調整に利用できます。
デフォルトメタデータ
以下の3つは自動で付与されます。
| フィールド | 内容 |
|---|---|
filename |
ファイル名 |
folder |
フォルダパス |
timestamp |
最終更新日時 |
カスタムメタデータ
上記に加えて、インスタンスごとに最大5つのカスタムフィールドを定義できます。対応する型は text(最大500文字)、number、boolean、datetime(ISO 8601)の4種類です。
こちらは 検索時の重み付け にも利用できます。
今回はCMSの記事データに合わせて、slug、first-published-at、author の3フィールドを追加しました。
追加方法は、インスタンス作成時に対話形式で設定する、REST APIの update で後から追加、ダッシュボードから追加があります。
custom_metadata:
- field_name: slug, data_type: text
- field_name: first-published-at, data_type: datetime
- field_name: author, data_type: text
これにより、検索時に...
- HITした記事の
slugを返す "author": "konishi-ryo"でフィルタするfirst-published-atの範囲で絞り込む
といったことが可能になります。
記事データのアップロード
Items APIを使って、記事データをAI Searchにアップロードします。CLIにはアップロードコマンドがないためREST APIを使います。
サポートされるファイル形式は幅広く、プレーンテキスト系(.md, .txt, .log など)はそのまま、リッチフォーマット(.pdf, .html, .docx, .xlsx, .csv など)はCloudflare側が自動でMarkdownに変換してからインデックスされます。
DevelopersIOのバックエンドでは記事をMarkdownで保存しており都合が良いです。
まずはCMSから下記の記事(タイトルと本文)をMarkdown形式でダウンロード、そのままCloudflareにアップロードしてみることにします。
MDファイルダウンロード後、Cloudflareへのアップロードはこんな感じ:
$ curl -X POST "https://api.cloudflare.com/client/v4/accounts/<ACCOUNT_ID>/ai-search/namespaces/konishi-test/instances/devio-search/items" \
-H "Authorization: Bearer <API_TOKEN>" \
-F "file=@articles.md" \
-F 'metadata={"slug":"n26-chargeback-ai","first-published-at":"2026-05-28T12:00:00Z","author":"konishi-ryo"}'
レスポンス:
{
"success": true,
"result": {
"id": "928ad9f2e3ed4535a81f7377d3731aa6",
"key": "article.md",
"status": "queued",
"next_action": "INDEX",
"namespace": "konishi-test",
"source_id": "builtin",
"created_at": "2026-05-29 15:24:09"
}
}
status: "queued" になっておりアップロード成功。インデックス処理は自動で始まります。stats を見ると Processing に入っているのがわかります。
$ pnpm wrangler ai-search stats devio-search --namespace
┌────────┬────────────┬─────────┬─────────┬──────────┬────────┐
│ Queued │ Processing │ Indexed │ Skipped │ Outdated │ Errors │
├────────┼────────────┼─────────┼─────────┼──────────┼────────┤
│ 0 │ 1 │ 0 │ 0 │ 0 │ 0 │
└────────┴────────────┴─────────┴─────────┴──────────┴────────┘
その後少し待つと Index されたことがわかります。
┌────────┬────────────┬─────────┬─────────┬──────────┬────────┐
│ Queued │ Processing │ Indexed │ Skipped │ Outdated │ Errors │
├────────┼────────────┼─────────┼─────────┼──────────┼────────┤
│ 0 │ 0 │ 1 │ 0 │ 0 │ 0 │
└────────┴────────────┴─────────┴─────────┴──────────┴────────┘
直接アップロードされたファイルは、ダッシュボードからも確認できます。
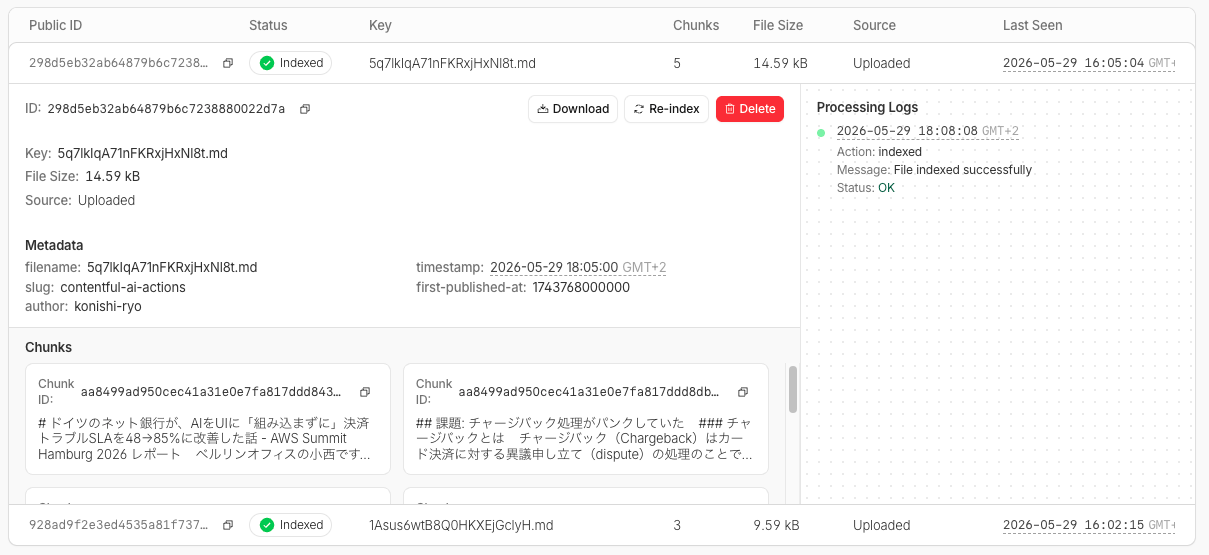
5つのチャンクに分割されてインデックスされました(後述しますがこの辺のパラメータも変更可)。ファイルサイズは14.59kBで、ステータスは「Indexed」となり、正常にインデックス処理が完了しています。
カスタムメタデータも確認できました。
検索してみる
インデックスが完了したら検索してみます。まずはCLIから。
$ wrangler ai-search search devio-search --namespace konishi-test --query "N26 決済トラブル AI"
Search query: "N26 決済トラブル AI" (6 results)
┌───┬────────┬───────────────────────────┬───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┬──────┐
│ # │ score │ key │ text │ type │
├───┼────────┼───────────────────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┼──────┤
│ 1 │ 0.7265 │ 5q7lkIqA71nFKRxjHxNl8t.md │ # ドイツのネット銀行が、AIをUIに「組み込まずに」決済トラブルSLAを48→85%に改善した話 - AWS Summit Hamburg 2026 レポート... │ text │
├───┼────────┼───────────────────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┼──────┤
│ 2 │ 0.5867 │ 5q7lkIqA71nFKRxjHxNl8t.md │ ## 安全性の担保 │ text │
│ │ │ │ │ │
│ │ │ │ 規制業界のため安全性は3つのレイヤーで担保しています。 │ │
│ │ │ │ │ │
│ │ │ │ **AI Guardrails**: 判定リクエストがAIに到達する前にバリデー... │ │
├───┼────────┼───────────────────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┼──────┤
│ 3 │ 0.5754 │ 5q7lkIqA71nFKRxjHxNl8t.md │ ## 課題: チャージバック処理がパンクしていた │ text │
│ │ │ │ │ │
│ │ │ │ ### チャージバックとは │ │
│ │ │ │ │ │
│ │ │ │ チャージバック(Chargeback)はカード決済に対する異議申し立て(dis... │ │
├───┼────────┼───────────────────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┼──────┤
│ 4 │ 0.5632 │ 5q7lkIqA71nFKRxjHxNl8t.md │ ## 学んだこと │ text │
│ │ │ │ │ │
│ │ │ │ Alex氏が共有してくれた3つの学びが下記です: │ │
│ │ │ │ │ │
│ │ │ │ **Lesson 1: まずインプットを直せ。** 導入前は自由テキスト1つとファイルア... │ │
├───┼────────┼───────────────────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┼──────┤
│ 5 │ 0.5580 │ 5q7lkIqA71nFKRxjHxNl8t.md │ ## ドメイン理解から始めた │ text │
│ │ │ │ │ │
│ │ │ │ Alex氏のチームはもともとチャージバックのUI提出フローと一部の自動化ルール(不正利用系)を担当していました。ただ、Autho... │ │
├───┼────────┼───────────────────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┼──────┤
│ 6 │ 0.4349 │ 1Asus6wtB8Q0HKXEjGclyH.md │ ## 注意点 │ text │
│ │ │ │ │ │
│ │ │ │ - AI Actionsはフィールド単位で実行されます。テキストの部分選択や、エントリー全体に対する適用は現時点ではできません。 │ │
│ │ │ │ - 権限管... │ │
└───┴────────┴───────────────────────────┴───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┴──────┘
6件中5件はN26記事の各チャンクがスコア順に並んでおり、記事単位ではなく分割されたチャンク単位で返ってくることがわかります。6件目にスコア0.43でテスト投入した別記事が混ざっていますが、「AI」というキーワードに引っ張られた結果です。
search コマンドには以下のオプションがあります。
| オプション | 説明 |
|---|---|
--max-num-results |
最大結果件数 |
--score-threshold |
最低スコア(0〜1) |
--reranking |
リランキングの有効/無効 |
--filter |
メタデータフィルタ(key=value、複数指定可) |
--json |
JSON形式で出力 |
--filter を使えば、先ほど設定したカスタムメタデータで絞り込めます。例えば特定の著者の記事だけを検索対象にする場合:
$ wrangler ai-search search devio-search --namespace konishi-test --query "AI" --filter author=konishi-ryo
--json を付けると、レスポンスにメタデータ(slug等)も含まれた形で返ってきます。スコア順で返ってくるため、Top-Kをそのまま使える形。
日本語検索の精度を簡易評価してみる
簡単に評価してみます。
評価方法
テストクエリと正解記事のペアを用意して Hit Rate@5で測定、Top-5の検索結果に正解記事が含まれているかどうかをシンプルに測ってみます。
テストクエリの設計
インデックス対象は約1,000件、テストクエリは50件としました。クエリは実際の検索行動に近づけるため、半角スペース区切りで最大4語のキーワード形式にしています。
結果
テスト実行結果です。
全体のHit Rate@5: 46/49 (93.9%)
50件中1件はTop-5の外(#6, #7)に落ちたものの正解記事自体はインデックスに存在しており、完全にミスしたのは3件でした。
ミスした3件を見ると、いずれもクエリが汎用的すぎて1,000件の中で特定の記事を指し切れないパターンです。例えば「障害 自動化 Bedrock」は、DevOps Agentの記事を期待していましたが、Bedrock関連の記事が多数存在するため他の記事に埋もれてしまいました。「システムプロンプト 改善」も、promptfooの記事を狙ったクエリですが、プロンプト改善に言及する記事は複数あり、ツール名を含めるなどしないと識別できませんでした。
コーパスが大きくなるほど意味的に近い記事が増え、汎用的なクエリでは特定の1記事をTop-5に入れづらくなってきます。
使ってみた所感
- セットアップが楽。データを突っ込むだけで検索が動く。自前でベクトル検索を構築しようとすると、DB選定・エンベディングモデル選定・チャンク戦略などを任せられる。
- 日本語の精度は、1,000件・50クエリの評価でHit Rate@5が93.9%。特定の記事を狙い撃ちするようなキーワードクエリなら大半が#1で返ってくる。汎用的なクエリでは同一トピックの記事に埋もれるケースがあるが、これはクエリ側の問題でもある。
- エージェント連携。MCPサーバーやWorkers bindingにも対応しているので、ブログの内容や外部ソースをベースに回答するチャットボットなども作れそう。
精度をさらに上げるには
今回の検証はデフォルト設定(ベクトル検索のみ)で行いましたが、AI Searchには他のオプションがあります。また、データの前処理で改善できる余地もあります。
AI Search側の設定
- Hybrid Search: キーワード検索を併用することで、「boto3」「postinstall」のような固有キーワードの一致に重みが付く。今回ミスした「Bedrock Claude boto3 Anthropic SDK 移行」のようなケースで効果が期待できる
- Query Rewrite: LLMがクエリを検索に適した表現に書き換えてから検索する。曖昧なクエリが具体化されることで精度が上がる可能性があるが、実際にどう書き換えられるかはCloudflare側のLLMに依存する
- Reranking: 初回検索の上位結果をLLMで再評価して並べ替える。Top-10には入っているがTop-5から漏れたケースに有効
データ側の工夫
- タイトルをカスタムメタデータに追加し、Boost byで重み付け: 利用可能なカスタムメタデータ5枠の中に記事タイトルを
text型フィールドとして追加し、Boost byに設定すればタイトルとの一致にスコアが加算される - 記事の要約をメタデータに追加: アップロード前にLLMで「この記事が解決する課題」等を要約し、メタデータに付与する。本文中に直接書かれていない表現(例: 「障害の一次調査を自動化する」など)が要約に含まれれば、汎用的なクエリでもヒットしやすくなる
- チャンクサイズの調整: デフォルトは1024トークン。大きくすると1チャンクに含まれる文脈が増えてセマンティック検索の精度が上がる反面、ノイズも増えるトレードオフがある
制御可能な値
AI Searchはチャンク分割やインデックス構築を自動でやってくれますが、いくつかのパラメータはインスタンス単位で調整できます。
ダッシュボードのインスタンス設定画面から確認・変更できます。主な項目は以下の通りです。
Embedding
| パラメータ | デフォルト値 | 説明 |
|---|---|---|
| Embedding model | @cf/qwen/qwen3-embedding-0.6b |
ベクトル化に使うモデル |
| Chunk size | 1024 tokens | チャンクあたりのトークン数 |
| Chunk overlap | 10% | 隣接チャンク間の重複率(0%〜30%) |
チャンク分割のアルゴリズムは recursive chunking(段落→文の順に自然な境界で再帰的に分割)で、変更はできません。Markdownの見出しなど構造的な区切りを意識して分割してくれるので、ブログ記事との相性は良いです。
Retrieval
| パラメータ | デフォルト値 | 説明 |
|---|---|---|
| Match threshold | 0.4 | 最低スコア。これ未満のチャンクは結果に含まれない |
| Maximum number of results | 10 | 返却する最大チャンク数 |
| Boost by | - | 特定のメタデータでスコアを重み付け |
その他のオプション
| 項目 | 説明 |
|---|---|
| Hybrid search | ベクトル検索とBM25(単語の出現頻度ベースの全文検索)キーワード検索を組み合わせる(デフォルト: OFF) |
| Query rewrite | 曖昧・口語的なクエリをLLMで検索に適した表現に書き換えてから検索する(デフォルト: OFF) |
| Reranking | 検索結果をLLMで再ランク付けする(デフォルト: OFF) |
| Similarity caching | 類似クエリの結果をキャッシュして高速化(デフォルト: ON、TTL 48時間) |
| Generation model | @cf/meta/llama-3.3-70b-instruct-fp8-fast。検索結果をもとに回答を生成する際のモデル |
設定はインスタンス作成後でも変更可能です。ダッシュボードまたはREST APIの update から変えられます。
制限について
Free planの主な制限です。
| 項目 | Free plan | Paid plan |
|---|---|---|
| ファイル数/インスタンス | 100,000 | 1,000,000(ハイブリッド検索は500,000) |
| ファイルサイズ上限 | 4 MB | 4 MB |
| クエリ数/月 | 20,000 | Unlimited |
| インスタンス数/アカウント | 100 | 5,000 |
今回CMSはContentfulのため1エントリ2MBの制限があり、4MBのファイルサイズ上限は問題ありませんでした。
月20,000クエリは検証用途なら十分。プロダクトに組み込むならPaid planが要ります。
まとめ
Cloudflare AI Searchを使って、DevIOの記事約1,000件を自然言語で検索できるようにしてみました。
データソースについて、今回はローカルからの直接アップロードで試しましたが、規模が大きくなればR2へのアップロードのほうが断然効率的ですね。
やったこと:
- Wrangler CLIでAI Searchインスタンスを作成
- CMSから記事をマークダウンで取得し、Items APIでアップロード
- CLIとREST APIで検索を試し、Hit Rate@5で日本語精度を簡易評価
デフォルト設定のベクトル検索のみでこの精度は、セットアップの手軽さを考えると十分かなと思いました。Hybrid SearchやQuery Rewriteなどのオプション、データ側の前処理を組み合わせればさらなる改善も見込めます。
ベータ中は無料なので、気になる人は触ってみてください。










